
聊天记忆
场景描述
大模型对话记忆针对具有深度学习能力的大型语言模型,它指的是模型在与用户进行交互式对话的过程中,能够追踪、理解并利用先前对话上下文的能力。此机制使得大模型不仅能够响应即时的输入请求,还能基于之前的交流内容能够在对话中记住先前的内容,并根据这些信息进行后续的响应。这种记忆机制使得模型能够在对话中持续跟踪和理解用户的意图和上下文,从而试下更自然和连贯的对话。
不带聊天记忆的场景
@Test
public void test() {
DashScopeApi dashscopeApi = new DashScopeApi("your-api-key");
DashScopeChatOptions dashScopeChatOptions = DashScopeChatOptions.builder()
.withModel(DashScopeApi.ChatModel.QWEN_MAX.getModel())
.build();
ChatClient chatClient = ChatClient.builder(new DashScopeChatModel(dashscopeApi, dashScopeChatOptions))
.defaultAdvisors(
).build();
String content = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("你是谁").call().content();
System.out.println(content);
String content1 = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("我是张三").call().content();
System.out.println(content1);
String content2 = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("我是谁").call().content();
System.out.println(content2);
}此时返回的结果为:
我是Qwen,由阿里云开发的超大规模语言模型。我的目标是帮助用户更高效地获取信息、创作内容、解决问题,以自然语言的方式实现与用户的交互。如果你有任何问题或需要帮助,都可以告诉我,我会尽力提供支持。
你好,张三!很高兴见到你。有什么我可以帮助你的吗?
您好!在我们的对话中,您是使用我(Qwen)服务的用户。不过,您的具体身份信息我并不知道,因为我被设计为尊重用户隐私,不会收集或存储个人身份信息。如果您是在询问更深层次的哲学问题“我是谁”,那么这可能需要您自己去探索和定义了。每个人都是独一无二的,通过经历、思考和个人成长来更好地了解自己。希望这个回答对您有所帮助!如果有其他想要讨论的话题,请随时告诉我。可以看到在第二句我们告诉了大模型,我们是谁,然后希望的是大模型能够记住我是谁,然后我们询问的时候回答我的问题。
使用ChtModel实现聊天记忆
@Test
public void test() {
DashScopeApi dashScopeApi = DashScopeApi.builder().apiKey(API_KEY).build();
ChatModel chatModel = DashScopeChatModel.builder().dashScopeApi(dashScopeApi).build();
// 第一次对话
UserMessage userMessage = new UserMessage("你是谁");
String aiResult = chatModel.call(userMessage);
System.out.println(aiResult);
// 第二次对话
UserMessage userMessage1 = new UserMessage("我是张三");
AssistantMessage assistantMessage = new AssistantMessage(aiResult);
String aiResult1 = chatModel.call(userMessage, assistantMessage, userMessage1);
System.out.println(aiResult1);
// 第三次对话
UserMessage userMessage2 = new UserMessage("我是谁");
AssistantMessage assistantMessage1 = new AssistantMessage(aiResult1);
String aiResult2 = chatModel.call(userMessage, assistantMessage, userMessage1, assistantMessage1, userMessage2);
System.out.println(aiResult2);
}返回结果:
我是通义千问,阿里巴巴集团旗下的超大规模语言模型。我可以帮助你回答问题、创作文字、提供信息查询等服务。如果你有任何需要,欢迎随时告诉我!
你好,张三!有什么我可以帮你的吗?😊
你是张三,刚刚告诉过我你的名字的。😊可以看到在后面再次询问模型的时候,它记住了第二次对话的内容,所以在第三次对话的时候返回了我们希望出现的信息。
使用ChatClient来实现的聊天记忆
现在我们在客户端交互的时候配置一个聊天记忆。
@Test
public void test() {
DashScopeApi dashscopeApi = new DashScopeApi("your-app-key");
DashScopeChatOptions dashScopeChatOptions = DashScopeChatOptions.builder()
.withModel(DashScopeApi.ChatModel.QWEN_MAX.getModel())
.build();
ChatClient chatClient = ChatClient.builder(new DashScopeChatModel(dashscopeApi, dashScopeChatOptions))
.defaultAdvisors(
// 配置一个聊天记忆的处理器
MessageChatMemoryAdvisor.builder(new InMemoryChatMemory()).build()
).build();
String content = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("你是谁").call().content();
System.out.println(content);
String content1 = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("我是张三").call().content();
System.out.println(content1);
String content2 = chatClient.prompt().advisors(advisor -> advisor.param("conversationId", 1)).user("我是谁").call().content();
System.out.println(content2);
}此时再看添加了聊天记忆之后的结果:
我是Qwen,阿里云开发的一款超大规模语言模型。我被设计用来帮助用户生成各种类型的文本,如文章、故事、诗歌、故事等,并能够根据不同的场景和需求提供信息和帮助。无论是创意写作还是解决实际问题,我都致力于提供支持和解决方案。有什么我可以帮到你的吗?
很高兴认识你,张三!有什么我可以帮到你的吗?无论是需要信息查询、创意灵感,还是解决具体问题,我都在这里为你提供帮助。
你是张三。有什么具体的事情或问题需要我帮你解决吗?其实这里的原理我们观看下面的三次接口的DEBUG结果就知道了。首先,我们需要知道每次我们跟大模型的交互其实就是一次就接口的调用,所以我们只需要比较三次接口调用的参数信息即可。
第一次接口调用
在第一次接口调用的时候,我们的传递的userText是“你是谁”,此时chatMemoryStor中是没有内容的。这个很好理解,因为是第一次调用。
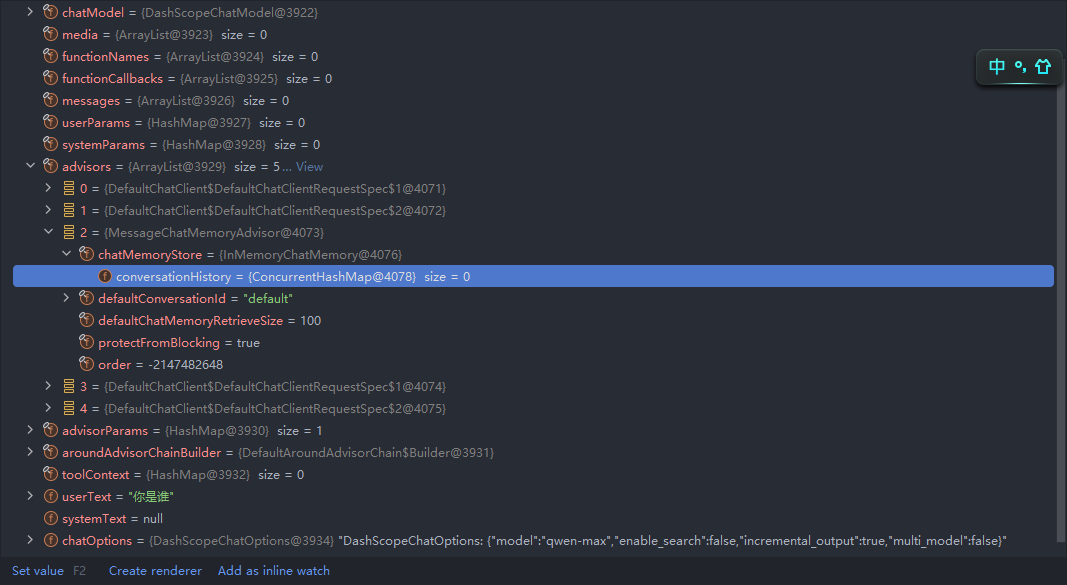
第二次接口调用
在第二次接口调用的时候,我们传递的userText是“我是张三”,此时再观察聊天记忆可以很明显看到里面有两条内容一条是userMessage类型的(我们发送给LLM的),一条是AssistantMessage类型的(LLM返回给我的信息),并且这两条信息就是我们第一次会话发送的消息和得到的结果。
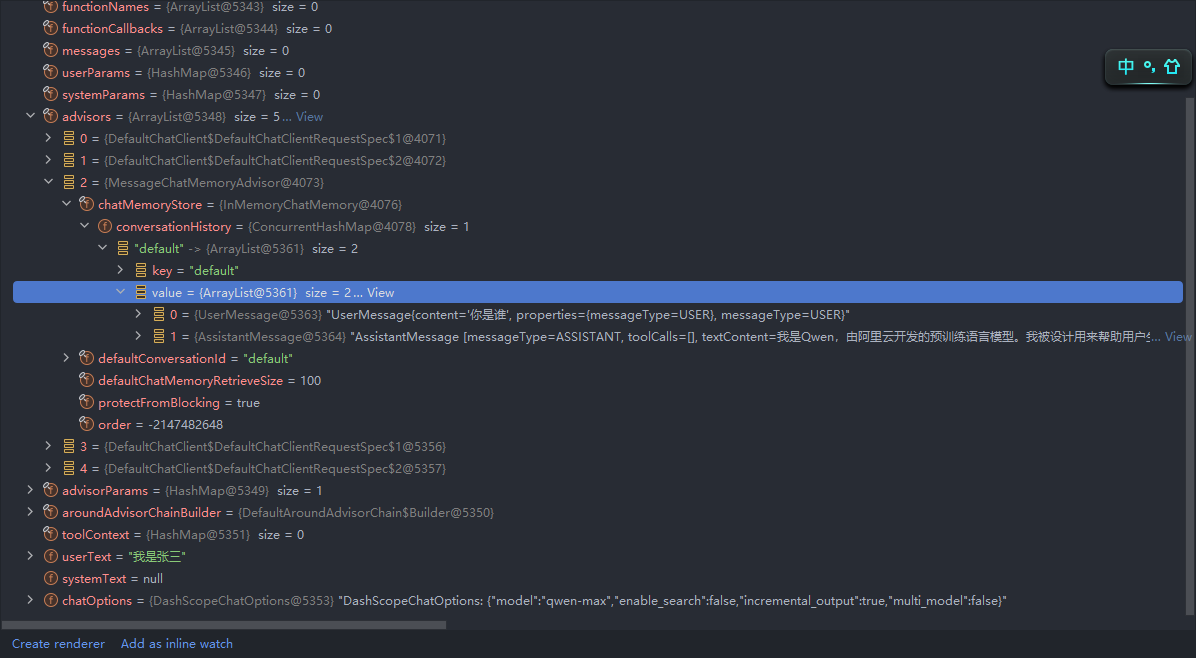
第三次调用接口
看了第二次接口调用的规则,其实就非常好理解了,继续观察聊天记忆中存储的内容,它不仅有第一次问答的内容,还有第二次问答的内容。
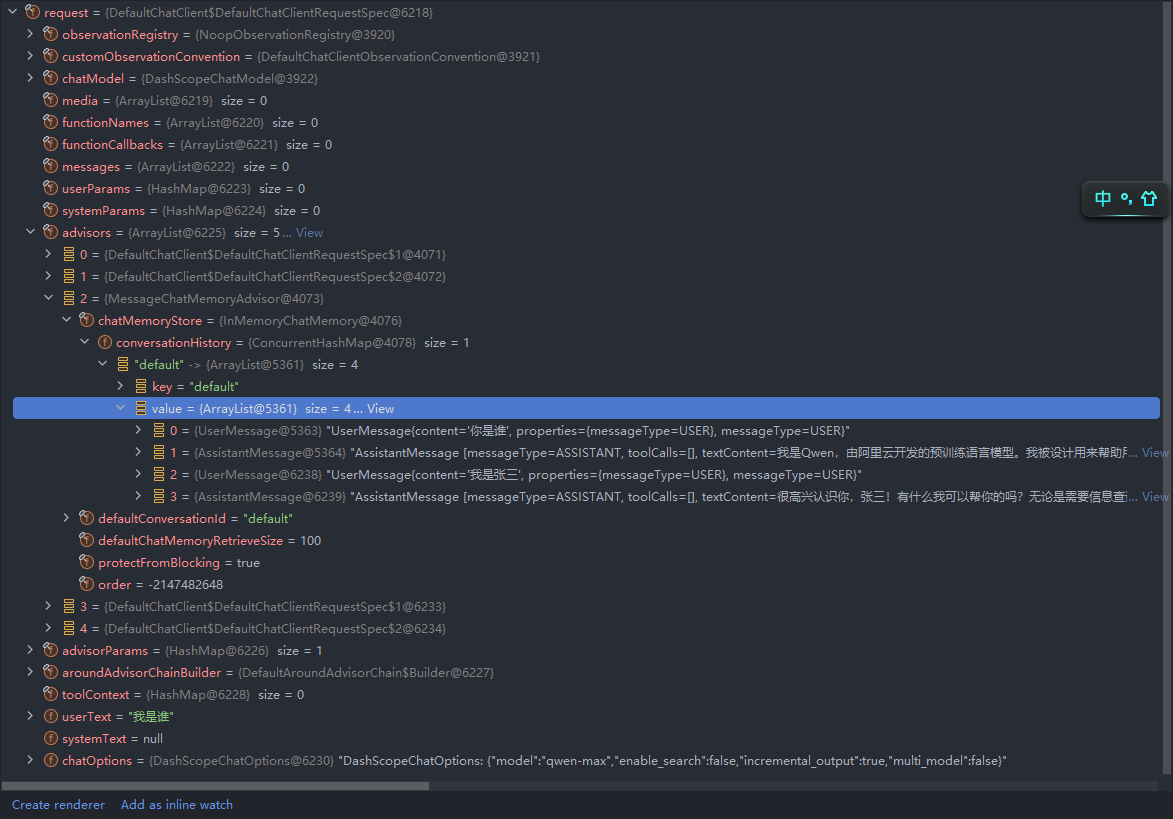
其实它的原理使用ChatModel是一样的,只不过在使用ChatClient的时候它能简化这个流程。
基本结构
按照上面的例子,我们不难直到聊天记忆的核心:
- 每次都是传递所有的历史消息,那么最多支持传递多少呢?如果我们跟大模型对话了1W轮,难道我要传递2W条对话?就算可以的话,那么大模型是否支持这么多的内容传递呢?
- 如果张三、李四作为用户都与大模型对话,那么我们怎么去区分不同人的聊天记忆呢?这么多的聊天记忆,难道只能放在内存中?能否借助比较熟悉的工具Redis、MySQL这种来存储呢?
基于上述两点疑问,ChatMemory的核心类有两个:MessageWindowChatMemory和ChatMemoryRepository。
MessageWindowChatMemory(聊天记忆窗口)
MessageWindowChatMemory是ChatMemory的实现类的,它的作用是每次都按照滑动窗口的方式来将最新的一定量的聊天记录作为聊天记忆传递给大模型。
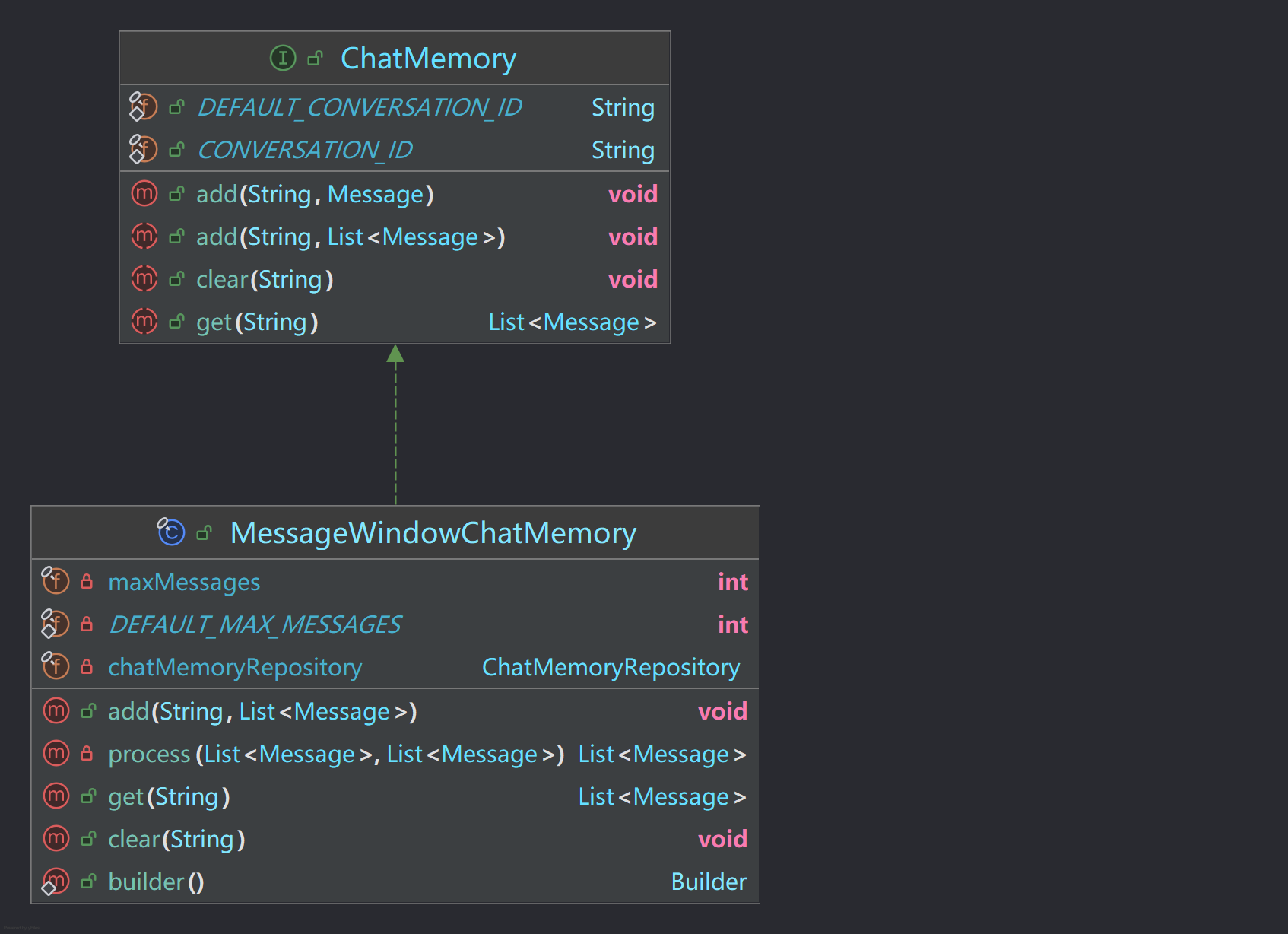
它的逻辑也是很简单的,根据源码我们很容知道DEFAULT_MAX_MESSAGES的值为20,即默认聊天记忆最大值为20。我们可以观察process()方法的源码就可以知道它的具体实现了:
/**
* memoryMessages:历史所有的聊天消息
* newMemoryMessage:新的聊天消息
*/
private List<Message> process(List<Message> memoryMessages, List<Message> newMessages) {
List<Message> processedMessages = new ArrayList();
// 对历史消息进行去重
Set<Message> memoryMessagesSet = new HashSet(memoryMessages);
Stream var10000 = newMessages.stream();
Objects.requireNonNull(SystemMessage.class);
// 重复的消息进行去重
boolean hasNewSystemMessage = var10000.filter(SystemMessage.class::isInstance).anyMatch((messagex) -> !memoryMessagesSet.contains(messagex));
var10000 = memoryMessages.stream().filter((messagex) -> !hasNewSystemMessage || !(messagex instanceof SystemMessage));
Objects.requireNonNull(processedMessages);
// 将本次的聊天记录和历史的聊天记录都加入到precessedMessages列表中
var10000.forEach(processedMessages::add);
processedMessages.addAll(newMessages);
// 如果processedMessages的长度没有超过maxMessage的限制,就直接返回processedMessages
if (processedMessages.size() <= this.maxMessages) {
return processedMessages;
} else {
// 如果processedMessages的长度超过lemaxMessage的限制,就对processedMessages进行裁剪
// 计算需要删除的个数
int messagesToRemove = processedMessages.size() - this.maxMessages;
// 裁剪之后的历史消息列表
List<Message> trimmedMessages = new ArrayList();
int removed = 0;
// 循环判断,截取列表中后maxMessage个的历史消息,作为新的聊天记忆信息
for(Message message : processedMessages) {
if (!(message instanceof SystemMessage) && removed < messagesToRemove) {
++removed;
} else {
trimmedMessages.add(message);
}
}
return trimmedMessages;
}
}在看上面的MessageWindowChatMemory的时候,也能看到另外一个关键的属性ChatMemoryRepository,这是是聊天记忆存储的方式,也引出了我们的第三个组件ChatMemoryRepository(聊天持久化方式)。
ChatMemoryRepository(聊天记忆的持久化方式)
在实际的应用开发过程中聊天记忆通常不会存储在内存中,会借助一些持久化的数据库来完成,例如Redis。MongoDB、MySQL等。
在Spring AI中它创建了ChatMemoryRepository接口,允许用户自定义来实现聊天记忆的功能,并且仅仅提供了InMemoryChatMemoryRepository实现(基于内存存储的聊天记忆仓库)。
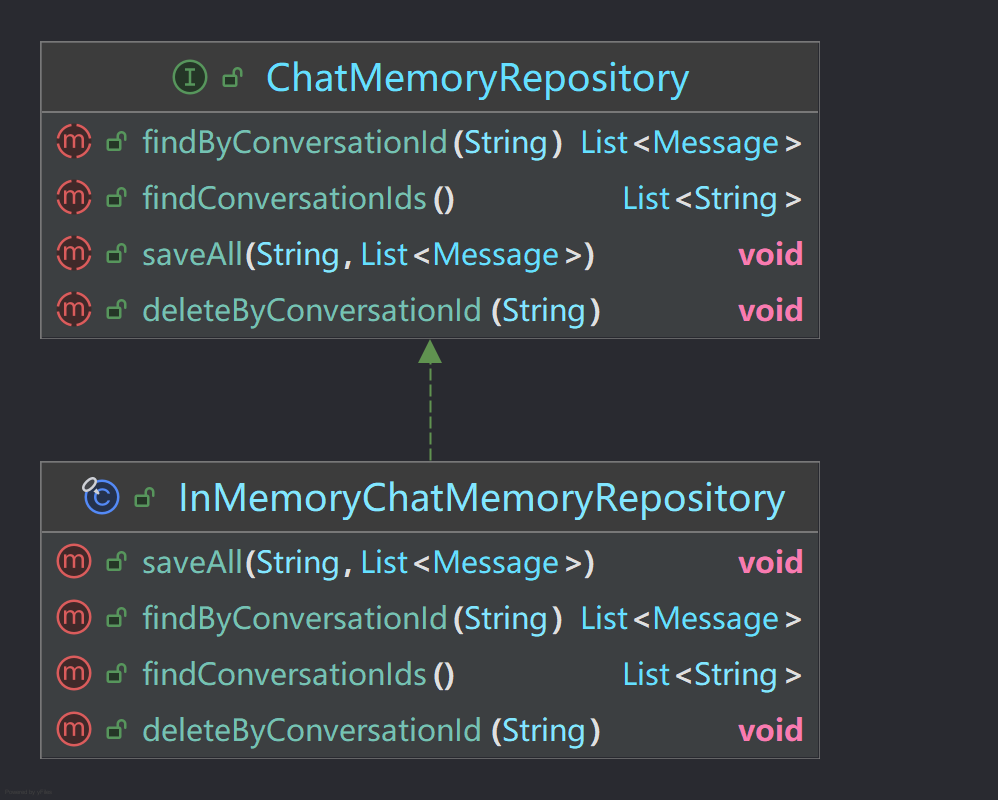
看到上面的类图其实也非常好理解,在ChatMemoryRepository接口中有四个方法:
findByConversationId(String conversationId):根据会话的ID查询出历史的会话记录;findConversationIds():获取所有的会话ID列表;saveAll(String conversationId,List<Message> messages):保存要传入的会话记录;deleteByConversionId(String conversataionId):删除conversationId下的历史会话记录;
实现其他形式的聊天记忆
基于Redis持久化的聊天记忆
如果我们需要基于Redis来进行聊天记忆的存储的话,在Spring AI Alibaba中其实已经有写好的实现了(com.alibaba.cloud.ai.memory.redis.RedisChatMemoryRepository,源码很好理解,这里不赘述了),我们只需要引入对应的依赖即可。
引入依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
</dependency>
<!--在spring-ali-alibaba-starter-memory-redis中使用到了,所有需要额外引入下-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>配置文件
spring:
data:
redis: # 添加Redis相关的配置信息
host: 127.0.0.1
port: 6379
password: xxxxxxxx注入RedisChatMemoryRepostiory
@Bean
public ChatClient chatClient(ChatModel chatModel,RedisChatMemoryRepository redisChatMemoryRepository) {
MessageWindowChatMemory messageWindowChatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(redisChatMemoryRepository)
.maxMessages(10)
.build();
return ChatClient.builder(chatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(messageWindowChatMemory).build())
.build();
}
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository() {
return new RedisChatMemoryRepository.RedisBuilder()
.host(host)
.port(port)
.password(password)
.build();
}编写测试代码
/**
* @param userId 会话Id
* @param message 内容
* @description 测试接口:<a href="http://localhost:8854/chat/template5?userId=7&message=3加4等于多少">测试连接</a>
*/
@GetMapping("/template5")
public String template5(@RequestParam("userId") String userId,
@RequestParam("message") String message) {
return chatClient.prompt()
.advisors(new Consumer<ChatClient.AdvisorSpec>() {
@Override
public void accept(ChatClient.AdvisorSpec advisorSpec) {
// 向prompt中添加conversationId参数信息
advisorSpec.param(ChatMemory.CONVERSATION_ID, userId);
}
})
.user(message)
.call().content();
}测试结果
// http://localhost:8854/chat/template5?userId=7&message=3加4等于多少
3加4等于7。
// http://localhost:8854/chat/template5?userId=7&message=再加3等于多少
7 再加 3 等于 10。
// 更换 userId http://localhost:8854/chat/template5?userId=8&message=%E5%86%8D%E5%8A%A03
你好!你提到“再加3”,但没有提供上下文。请问你是想在某个数字上加3,还是在某个列表、计算、代码或其他内容中“再加3”?可以提供更多信息吗?这样我才能更准确地帮你!😊这个时候,我们观察下redis里面的数据:

在Redis里面可以看到spring_ai_alibaba_chat_memory:7的Key,类型为List,里面存储的都是之间交互的Message。
这里为什么会这样存储,可以看下RedisChatMemoryRepository这个类的具体实现,其实很好理解,里面都是对Redis的一些操作。