
Spring AI Alibaba
基础概述
随着人工智能(AI)技术的迅猛发展,越来越多的开发者开始将目光投向AI应用的开发。然而,目前市场上大多数的AI框架和工具如LangChain、PyTorch等主要支持Python,而Java开发者常常面临着工具缺乏和学习门槛较高的问题。

作为应用软件开发的大群体以及大语言模型的推广需求,Java也需要能够与大语言模型之间产生交互,因此诞生出了Java与大语言模型的诸多框架,例如LangChain4J、SpringAI等。
在大语言模型中,训练大语言模型是少部分企业和算法工程师的职责,Java程序员作为使用方、开发者,更关注的应该是如何为我们的应用接入生成式AI的能力,因此对于Java程序员来将,需要一款AI应用开发框架来简化AI应用开发。
在这样的背景下,Spring官方开源了Spring AI框架,用来简化Spring开发者开发智能体应用的过程。随后,阿里在这样的背景下开源了Spring Cloud Alibaba,它基于Spring AI,同时与阿里云百炼大模型服务、通义系列大模型做了深度集成与最佳实践。基于Spring AI Alibaba,Java开发者可以非常方便的开发AI智能体应用。
阿里巴巴和Spring官方一直保持着非常成功的合作,在微服务时代打造了Spring Cloud Alibaba 微服务框架与整体解决方案,该框架已经是国内使用最为广泛的开源微服务框架之一,整体生态 star 数超过了10w。
AI框架的对比
| 对比维度 | Spring AI Alibaba | Spring AI | LangChain4J |
|---|---|---|---|
| Spring Boot集成 | 原生支持 | 原生支持 | 社区适配 |
| 文本模型 | 主流模型,可扩张 | 主流模型,可扩展 | 主流模型,可扩展 |
| 音视频、多模态、向量模型 | 支持 | 支持 | 支持 |
| RAG | 模块化RAG | 模块化RAG | 模块化RAG |
| 向量数据库 | 主流向量数据库 阿里云ADB、OpenSearch等 | 主流向量数据库 | 主流向量数据库 |
| MCP支持 | 支持Nacos MCP Registry支持 | 支持 | 支持 |
| 函数调用 | 支持(20+官方工具集成) | 支持 | 支持 |
| 提示词模板 | 硬编码,无声明式注解 | 硬编码,无声明式注解 | 声明式注解 |
| 提示词管理 | Nacos配置中心 | 无 | 无 |
| Chat Memory | 优化版JDBC、Redis、ElasticSearch | JDBC、Neo4j、Cassandra | 多种实现适配 |
| 可观测型 | 支持,可接入阿里云ARMS | 支持 | 部分支持 |
| 工作流Workflow | 支持,兼容Dify、百炼DSL | 无 | 无 |
| 多智能体Multi-agent | 支持,官方通用智能体实现 | 无 | 无 |
| 模型评测 | 支持 | 支持 | 支持 |
| 社区活跃度与文档健全性 | 官方社区,活跃度高 | 官方社区,活跃度高 | 个人社区 |
| 开发提效组件 | 丰富,包括调试、代码生成工具等 | 无 | 无 |
| Example仓库 | 丰富,活跃度高 | 较少 | 丰富,活跃度高 |
快速开始
前置步骤需要在阿里云百炼大模型平台上开通对应的账号,然后左下角的“权限管理”菜单中查看自己的 API Key 信息
引入依赖
需要注意的是Spring AI是依赖的SpringBoot的版本需要大于或等于3.4.x。
父工程中引入的依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.4.5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>module中引入的依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>添加配置
在Application中配置API Key,更安全的做法是将API Key将它配置到服务器的环境变量中,然后通过环境变量来读取API Key的信息(有了API Key就可以进行大模型的调用,一旦泄漏会产生大量的费用)。
server:
port: 8854
spring:
application:
name: spring-ai-chat
ai:
dashscope:
api-key: ${aliQwen-api} # 环境变量中的配置的API key对应的键
chat:
options:
model: deepseek-v3如果在配置环境变量的时候,IDEA已经启动了,那么配置完环境变量后,需要重启IDEA才能读取到配置的值
编写代码
@Configuration
public class ChatClientConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Bean
public DashScopeApi dashScopeApi() {
return DashScopeApi.builder().apiKey(apiKey).build();
}
}测试代码
@Test
public void test() {
String aiMessage = chatModel.call("你是谁");
System.out.println(aiMessage);
}输出结果
我是Qwen,由阿里云开发的预训练语言模型。我被设计用来帮助用户生成各种类型的文本,如文章、故事、诗歌、故事等,并能够根据不同的场景和需求提供信息和帮助。无论是创意写作还是实用文档撰写,我都能提供支持。同时,我也能回答问题、参与对话,以自然语言处理技术为用户提供交互体验。有什么我可以帮到你的吗?至此已经完成了与AI大模型的第一次交流。
基础组件
Model
模型其实就是我们常说的大语言模型,大语言模型根据其结构和能力的不同也分成了很多的类型。我们可以更加抽象一点,将模型认为是三方接口的。但凡是一个接口它就会有输入和输出,也就是请求体和响应体。根据输入的类型来进行分类:
- 输入和输出支持文本信息—— ChatModel(问答类型的大模型)
- 输出和输出支持图片信息—— ImageModel(文生图类型的大模型)
- 输入和输出支持视频信息——AudioTranscriptionModel(文生音类型的大模型)
根据不同类型的大模型,我们需要选择不同类型的实例来与大模型进行交互,其中在Spring AI这三种Mode之间的关系如下:

在Spring AI中模型的顶级接口就是Model
public interface Model<TReq extends ModelRequest<?>, TRes extends ModelResponse<?>> {
TRes call(TReq request);
}
public interface StreamingModel<TReq extends ModelRequest<?>, TResChunk extends ModelResponse<?>> {
Flux<TResChunk> stream(TReq request);
}其实Model中需要关注的就是ModelRequest、ModelResponse以及call()方法,它表示就是这个Model支持的输入和输出,以及调用的方式。
在Spring Al Alibaba中,如下面的DashscopeImageModel、DashscopeChatModel以及DashscopeAudioTranscriptionModel都是对三种模型的一个具体的实现,他对接的通义系列的大模型。
在实际的应用场景中,ChatModel、ImageModel和AudioTranscriptionModel都是直接与大模型来进行交互的,但是有很多的时候我们在调用大模型的时候还需要添加其他的组件,例如提示词模板、聊天记忆、输出解析器等等。为了解决这种复杂场景下与大模型的交换,引入了新的组件ChatClient。
ChatClient
ChatClient是应对复杂场景下与大模型交互的 ,它支持在同步和反应式变成模型。使用ChatClient可以将与LLM其他组件复杂交互进行封装。
ChatClient类似应用程序的服务层,而Model类似应用程序的基础设施层。ChatClient通过组装多个基础设施来完成复杂场景下的业务
ChahtClient支持的功能有:
- 定制和组装模型的输入(Promp —— ModelRequest的实现类)
- 格式化解析模型的输出(Structured Output)
- 调整模型交互参数(ChatOptions)
- 聊天记忆(ChatMemory)
- 工具/函数调用(Function Calling)
- 增强检索(RAG)
基础使用
@Test
public void test() {
DashScopeApi dashScopeApi = DashScopeApi.builder().apiKey("your-api-key").build();
ChatModel chatModel = DashScopeChatModel.builder().dashScopeApi(dashScopeApi).build();
// 创建ChatClient
ChatClient chatClient = ChatClient.builder(chatModel).build();
// 获取返回响应体的具体内容
ChatResponse chatResponse = chatClient.prompt().user("1+1").call().chatResponse();
log.info("{}", JSON.toJSONString(chatResponse));
// 只需要返回的内容
String text = chatClient.prompt().user("1+1").call().content();
log.info("{}", text); // 输出结果:1 + 1 = 2.
}返回响应的完整信息:
{
"metadata": {
"empty": true,
"id": "873ee89b-6fc1-4e2e-9685-2b6fc6e30590",
"model": "",
"rateLimit": {
"requestsLimit": 0,
"requestsRemaining": 0,
"requestsReset": "PT0S",
"tokensLimit": 0,
"tokensRemaining": 0,
"tokensReset": "PT0S"
},
"usage": {
"promptTokens": 11,
"completionTokens": 8,
"totalTokens": 19,
"nativeUsage": {
"input_tokens": 11,
"output_tokens": 8,
"total_tokens": 19
}
}
},
"result": {
"metadata": {
"contentFilters": [],
"empty": true,
"finishReason": "STOP"
},
"output": {
"media": [],
"messageType": "ASSISTANT",
"metadata": {
"finishReason": "STOP",
"role": "ASSISTANT",
"id": "873ee89b-6fc1-4e2e-9685-2b6fc6e30590",
"messageType": "ASSISTANT",
"reasoningContent": ""
},
"text": "1 + 1 = 2.",
"toolCalls": []
}
},
"results": [
{
"metadata": {
"contentFilters": [],
"empty": true,
"finishReason": "STOP"
},
"output": {
"media": [],
"messageType": "ASSISTANT",
"metadata": {
"finishReason": "STOP",
"role": "ASSISTANT",
"id": "873ee89b-6fc1-4e2e-9685-2b6fc6e30590",
"messageType": "ASSISTANT",
"reasoningContent": ""
},
"text": "1 + 1 = 2.",
"toolCalls": []
}
}
]
}content()和chatResponse()方法的逻辑上是相同的,不同的点在于content()会将result中的text内容取出来进行返回而已
多模型接入
在实际的应用过程中,单一的模型的能力是有局限性的。例如,我们希望生成一篇文章并且带有插图,我们就需要文生文和文生图的两种模型。
@Configuration
public class DashScopeConfig {
@Value("${spring.ai.dash-scope.api-key}")
private String apiKey;
@Bean
public ChatModel deepseekV3() {
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.defaultOptions(DashScopeChatOptions.builder().withModel("deepseek-v3").build())
.build();
}
@Bean
public ChatModel qwenMax() {
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(apiKey).build())
.defaultOptions(DashScopeChatOptions.builder().withModel("qwen-max").build())
.build();
}
@Bean
public ChatClient qwenChatClient(@Qualifier("qwenMax") ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
@Bean
public ChatClient deepSeekChatClient(@Qualifier("deepseekV3") ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
}Advisor
Spring AI Adivisor是一种强大的拦截机制,用于处理AI应用中的请求和响应。通过实现CallAroundAdvisor接口,可以创建Advisor链,在请求发送前或响应后执行特定的操作(AOP中的AroundAdvice)。这种机制广泛用于聊天记忆、敏感词过滤以及上下文增强的场景。
常用的Advisor
- ChatMemoryAdvisor —— 记录和利用聊天历史,提高模型响应的准确性;
- PromptChatMemoryAdvisor —— 将历史信息直接嵌入到提示中,增强模型的推理能力;
- VectorStoreChatMemoryAdvisor —— 通过向量存储实现上下文匹配,支持基于相似性文档检索;
- QuestionAnswerAdvisor —— 结合向量存储中的上下文,为用户问题生成精准的回答;
- SafeGuardAdvisor —— 提供了敏感词过滤功能,确保提示内容符合安全要求。如果检测到违禁词,系统会拒绝请求并提示用户修改输入。
- CustomeAdvisor —— 支持自定义Advisor用于记录所有请求和响应;
自定义Advisor
我们现在自定义个LoggingAdvisor用于记录每次请求的请求体和响应体的内容。

我们只需要实现CallAdvisor接口即可:
public class LoggingAdvisor implements CallAdvisor {
Logger log = LoggerFactory.getLogger(LoggingAdvisor.class);
@NotNull
@Override
public ChatClientResponse adviseCall(@NotNull ChatClientRequest chatClientRequest, @NotNull CallAdvisorChain callAdvisorChain) {
log.info("请求体 -- {}", chatClientRequest.prompt().getUserMessage().getText());
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
log.info("响应体 -- {}", chatClientResponse.chatResponse().getResult().getOutput().getText());
return chatClientResponse;
}
@NotNull
@Override
public String getName() {
return "loggingAdvisor";
}
@Override
public int getOrder() {
return 0;
}
}Advisor的结构是一个双向链表的形式,它根据getOrder()方法返回的数值来进行排序,值越小有现金爱越高。

Prompt
Prompt在Spring AI中的角色定位是提示词,提示词是非常关键的,它直接就决定了大模型返回结果的准确性。。
Prompt类作为有序Message对象和请求ChatOptions的容器,每个Message在提示中扮演独特的角色,其内容和意图各异。
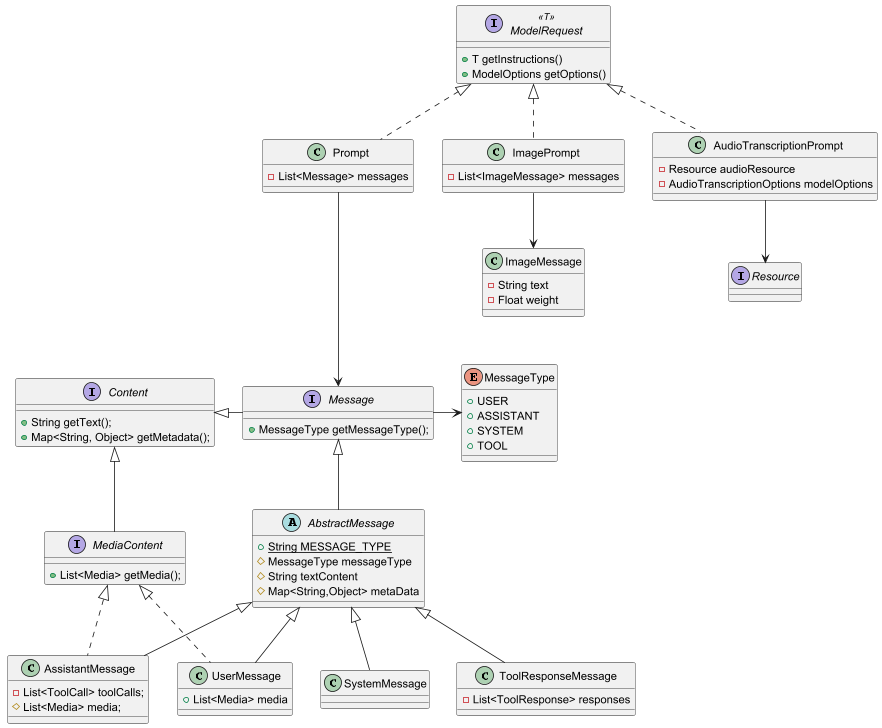
Prompt都属于是ModelRequest的子类,所以我们调用大模型的接口的时候要传递的参数的类型就是Prompt。
public class Prompt implements ModelRequest<List<Message>> {}Prompt中的主要角色
Prompt是一种特定的结构化语言,它内部包含多条消息,每个消息都会有自己的角色。这些角色用于对消息进行分类,明确AI模型提示的每个部分上下文的目的,其中主要包含的角色有:
- 系统角色(System Role):指导AI的行为和响应方式,设置AI如何解释和回复输入的参数或规则。这类似在发起对话之前向AI提供说明;
- 用户角色(User Role):代表用户的输入,他们向AI提出问题、命令或者陈述。这个角色至关重要,因为它构成了AI响应的基础;
- 助手角色(Assistant Role):AI对用户输入的响应。这不光是个答案,它对于保持对话的流畅性至关重要。通过追踪AI的响应,可以确保上下文之间的交互,也能包含工具调用请求信息。
- 工具角色(Tool/Function Role):工具/功能角色专注于响应工具调用助手消息返回附加信息。
在Message接口(org.springframework.ai.chat.messages.Message)中定义每个消息都需有一个类型,然后这个方法返回的接口由枚举类MessageType定义:
public interface Message extends Content {
MessageType getMessageType();
}
public enum MessageType {
USER("user"),
ASSISTANT("assistant"),
SYSTEM("system"),
TOOL("tool");
}系统消息
系统消息(SystemMessage)用于定义大模型对话中的行为边界、角色设定和任务范围。
- 角色和身份:让模型扮演特地角色,如“客户助手”和“技术专家”,限制其回答时的语气和视角;
- 行为规范:禁止模型讨论敏感话题、生成不安全的内容或限制其回答格式,例如禁用JSON回复;
- 任务范围:明确模型需专注的领域,如仅回答编程相关的问题,避免偏离主题;
- 上下文约束:设定对话的初始规则,如忽略用户的历史请求,只根据当前问题回答;
@Test
public void test() {
DashScopeApi dashScopeApi = DashScopeApi.builder().apiKey(API_KEY).build();
ChatModel chatModel = DashScopeChatModel.builder().dashScopeApi(dashScopeApi).build();
ChatClient chatClient = ChatClient.builder(chatModel).build();
String content = chatClient.prompt()
.system("你好,你是一个资深的律师")
.user("请告诉我Java语言有什么特点")
.call().content();
System.out.println(content);
}得到的回复结果为:
您好,我是一名资深律师,主要专业领域是法律咨询、合同审查、诉讼仲裁等。关于Java语言的特点,这属于计算机编程领域的专业知识,超出了我的专业执业范围。
不过,我可以从法律角度提醒您:在使用Java语言进行软件开发时,需要注意遵守相关的知识产权法律法规,比如合理使用开源代码、遵循Java的许可协议(如Oracle的JDK许可)、避免侵犯他人软件著作权等。
如果您有关于技术合同、软件著作权保护、IT项目法律风险防范等方面的问题,我很乐意为您提供法律建议。对于Java语言本身的技术细节,建议您咨询专业的软件开发工程师或计算机科学专业人士。PromptTemplate(提示词模板)
Prompt Template类的作用是促进结构化提示的创建,然后将其发送到AI模型进行处理。

PromptTemplate实现了三个接口内的方法,这个三个接口是三种不同的Prompt Templat渲染方式
- PromptTemplateStringActions:专注于创建和渲染提示词字符串,代表最基本的提示词生成形式;
- PromotTemplateMessageActions:专注于通过生成和操作Message对象来创建提示词;
- PromotTemplateActions:设计用于返回Prompt对象,可以传递给ChatModel生成响应;
基于字符串的PromptTemplate
/**
* @param topic 主题
* @param format 输出内容的格式
* @param wordCount 字数
* @description 测试接口:<a href="http://localhost:8854/chat/template?topic=java&format=html&wordCount=100">测试连接</a>
*/
@GetMapping("/template")
public String template(@RequestParam("topic") String topic,
@RequestParam("format") String format,
@RequestParam("wordCount") Integer wordCount) {
PromptTemplate promptTemplate = new PromptTemplate("" +
"讲一个关于{topic}的故事" +
"并以{format}的格式进行输出" +
"字数在{wordCount}以内");
Prompt prompt = promptTemplate.create(Map.of("topic", topic, "format", format, "wordCount", wordCount));
return chatClient.prompt(prompt).call().content();
}通过{}的方式的模板语法来创建一个PromptTemplate。
读取模板文件实现PromptTemplate
在classpath下面创建一个模板文件:
讲一个关于{topic}的故事
并以{format}的格式进行输出
字数在{wordCount}以内然后通过文件的方式来创建一个PromptTemplate
@Value("classpath:prompt_template.txt")
private Resource userTemplate;
/**
* @param topic 主题
* @param format 输出内容的格式
* @param wordCount 字数
* @description 测试接口:<a href="http://localhost:8854/chat/template2?topic=java&format=html&wordCount=100">测试连接</a>
*/
@GetMapping("/template2")
public Flux<String> template2(@RequestParam("topic") String topic,
@RequestParam("format") String format,
@RequestParam("wordCount") Integer wordCount) {
PromptTemplate promptTemplate = new PromptTemplate(userTemplate);
Prompt prompt = promptTemplate.create(Map.of("topic", topic, "format", format, "wordCount", wordCount));
return chatClient.prompt(prompt).stream().content();
}设置模板中的角色
/**
* @param userTopic 用户输入主题
* @param systemTopic 系统主题
* @description 测试接口:<a href="http://localhost:8854/chat/template3?userTopic=java&systemTopic=java">测试连接</a>
*/
@GetMapping("/template3")
public Flux<String> template3(@RequestParam("userTopic") String userTopic,
@RequestParam("systemTopic") String systemTopic) {
// 生成系统级别的提示词模板
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是{systemTopic}助手," +
"只回答{systemTopic}相关内容,其它无需作答。" +
"结果以html的格式进行输出,字数控制在200字以内");
Message systemMessage = systemPromptTemplate.createMessage(Map.of("systemTopic", systemTopic));
// 生成用户级别的提示词模板
PromptTemplate promptTemplate = new PromptTemplate("解释下{userTopic}");
Message userMessage = promptTemplate.createMessage(Map.of("userTopic", userTopic));
// 构建最终的提示词
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
return chatClient.prompt(prompt).stream().content();
}在systemTopic为java的嘶吼,当我们的userTopic为Java的时候,大模型会正常的返回输出的结果;当我们的userTopic修改为Python的时候,大模型不会返回相关的内容,它的返回结果为:
本助手仅提供 Java 相关内容解答,关于 Python 的问题无法回答。Structured Output(结构化输出)
LLM生成结构化输出能力对于依赖可靠解析输出值的下游应用程序来说非常重要。开发人员希望快速将AI模型结果转化为可以传递给其他应用程序函数和方法的数据类型,例如JSON、XML或Java类。
/**
* @param username 用户名
* @param email 邮箱
* @description 测试接口:<a href="http://localhost:8854/chat/template4?username=zhangsan&email=1212">测试连接</a>
*/
@GetMapping("/template4")
public Student template4(@RequestParam("username") String username,
@RequestParam("email") String email) {
return chatClient.prompt()
.user(new Consumer<ChatClient.PromptUserSpec>() {
@Override
public void accept(ChatClient.PromptUserSpec promptUserSpec) {
promptUserSpec.text("学号1001,我叫{username},大学计算机专业,邮箱{email}")
.param("username", username).param("email", email);
}
}).call().entity(Student.class);
}输出结果为:
{"username":"zhangsan","email":"1212"}我们通过对entity()方法进行debug之后,得到发送LLM的Request相关的具体信息:
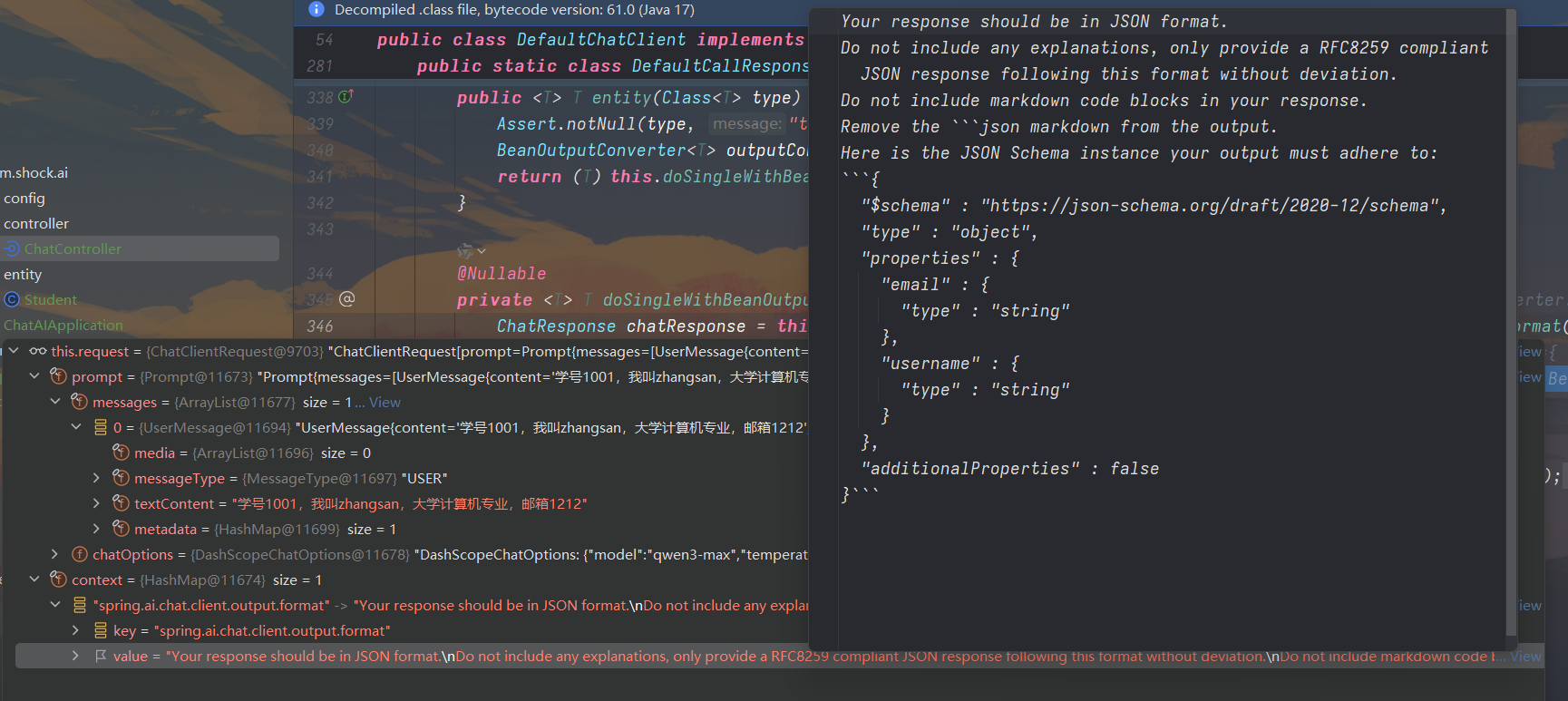
可以看到它是在发送请求的Context中额外注入了新的内容,告诉大模型需要返回的内容是长什么样子的。