
MySQL体系架构
MySQL的体系架构
MySQL的整体体系分四层结构:网络接入层、服务层、存储引擎和文件系统层。
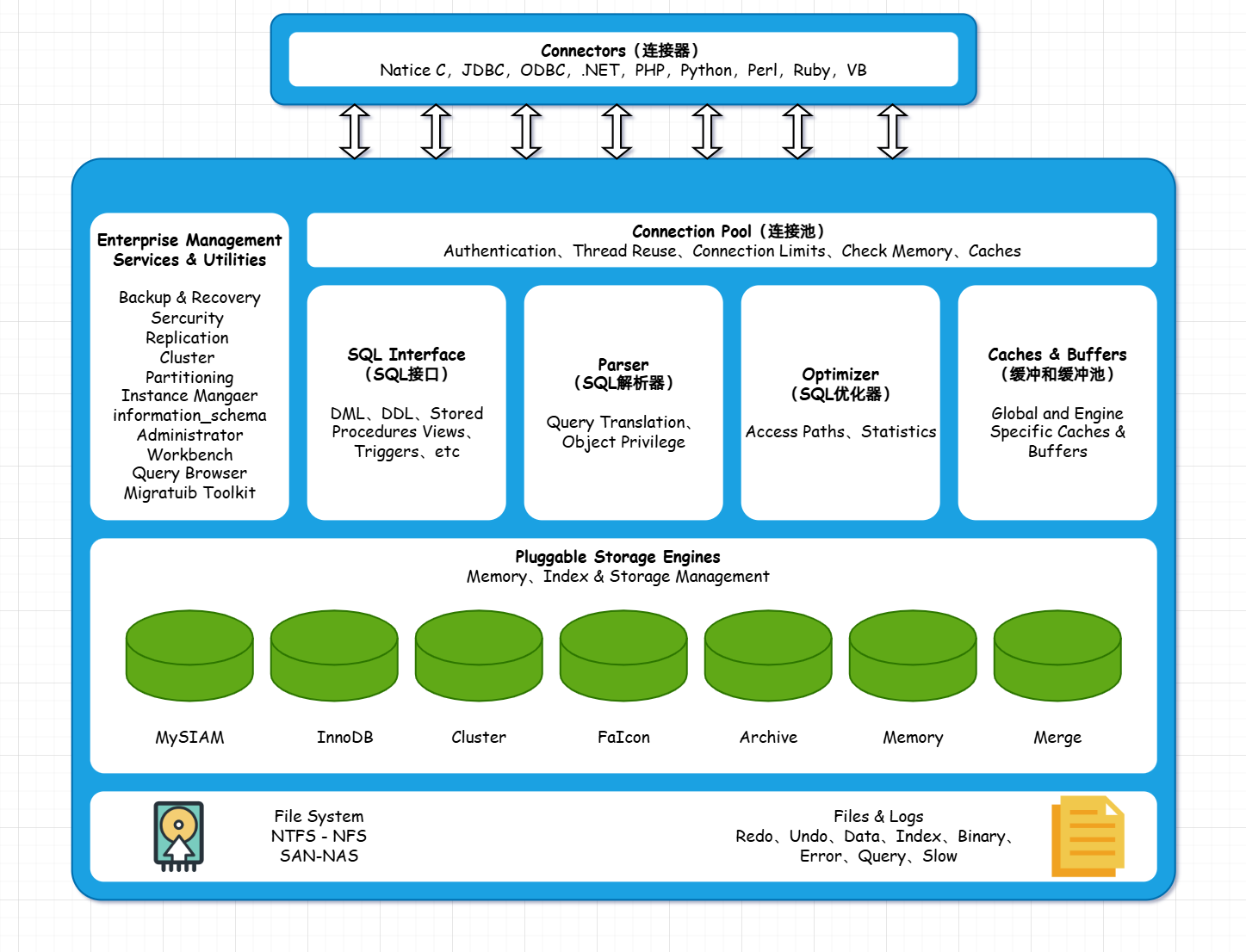
网络接入层
网络计入层是MySQL服务器与客户端之间的桥梁,负责处理客户端的连接请求、身份验证、权限检查以及连接池管理;
客户端连接器(Client Connectors)
提供与MySQL服务器建立连接的支持,目前几乎所有主流的服务器技术,例如常见的Java、Python、C、.NET等,它们通过各自的API技术与MySQL建立连接。
服务层
服务层是MySQL的核心部分,负责解析SQL查询、优化查询、执行查询操作并将结果返回客户端。
连接池
MySQL提供了内置的连接池功能(从MySQL 8.0开始),用于管理多个客户端连接。连接池可以减少频繁创建和销毁连接的开销,提升系统的并发处理能力。
系统管理和控制工具
用于备份恢复、安全管理、集群、管理等。
SQL接口
用于接收客户端发送的各种SQL命令,并且返回用户需要查询的结果,比如DDL、DML、存储过程、视图和触发器等。
解析器
解析器负责将SQL语句转换为内部语法树结构,它会检查语法是否正确,并生成相应的执行计划。
查询优化器
查询优化器是SQL层的核心组件之一,负责选择最优的查询执行计划。优化器会根据表的统计信息(如索引、表大小、数据分布等)评估不同的执行路径,并选择最高效的方案。优化器的目标是减少I/O操作、降低CPU的使用率,从而提高查询性能。
执行器
执行器根据优化器生成的执行计划,调用存储引擎层的接口来实际执行查询操作。执行器负责处理各种SQL操作,如SELECT、INSERT、UPDATE、DELETE等。
缓存
缓存机制是由一系列小缓存组成。比如表缓存、记录缓存、权限缓存、引擎缓存、索引缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据,用于加速数据读取操作。
MySQL曾经提供过一个查询缓存功能,用于缓存查询结果,如果相同的查询再次执行,MySQL可以直接从缓存中返回结果,而不需要重新执行查询。虽然查询缓存可以提高某些场景下的性能,但在高并发写入情况下,它的效果可能适得其反,因此在现代版本中已被移出。
在MySQL 8.0中查询缓存已经被废弃了
性能较差
1️⃣全局锁粒度:查询缓存使用粗粒度锁机制,任何对表的写操作(INSERT、UPDATE和DELTE)都会导致整个表的查询缓存失效;
2️⃣高并发写入瓶颈:在高并发写入场景下,频繁的缓存失效和刷新会造成严重的锁竞争,反而降低整体性能;
缓存命中率低下
1️⃣动态查询不适用:包含变量、函数、时间戳等动态内容查询难以缓存;
2️⃣数据更新频繁:写入操作多的表缓存命中率极低;
内部资源消耗过大
1️⃣内存管理开销:维护查询缓存需要消耗大量的内存资源;
2️⃣碎片化问题:缓存内存容易产生碎片,需要定期整理;
3️⃣配置复杂度:需要合理设置
query_cache_size、query_cache_min_res_unit等参数;严格的匹配规则
1️⃣字节级匹配:查询语句必须完全一致(包括空格、大小写)才能命中缓存;
2️⃣会话参数敏感:不同连接参数或字符集设置会导致缓存无法命中;
总结下来其实就是性能交叉,在高并发场景下会成为瓶颈。造成性能较差的原因是锁粒度太粗了、缓存命中率较低导致的。
存储引擎层
存储引擎层是MySQL的关键组成部分,负责实际数据的存储与提取,与底层系统文件进行交互。MySQL支持多种存储引擎,每种存储引擎都有其独特的特性和适用场景。现在有很多存储引擎,各有各的特点,最常见的时MyISAM和InnoDB。
| 存储引擎 | 描述 |
|---|---|
| InnoDB | 默认存储引擎(MySQL 5.7之后开始),支持事务、外键约束、行级锁和崩溃恢复。InnoDB是大多数生产环境的首选,特别适用于需要高并发写入和事务安全的场景。 |
| MyISAM | 早期MySQL的默认存储引擎,不支持事务和行级锁,但具有较高的读取性能。MyISAM适合只读或读多写少的场景,但由于其缺乏事务支持,现在已较少使用。 |
| Memory | 将数据存储在内存中,适用于临时表或需要快速读写的场景。由于数据存储在内存中,重启后数据会丢失,因此不适合持久化存储 |
| NDB Cluster | 用于分布式集群的存储引擎,支持高可用性和水平扩展。NDB Cluster通过分片技术奖数据分布在多个节点上,适合需要处理大规模数据集和高并发访问的场景 |
| Archive | 专门用于归档数据的存储引擎,适合存储大量历史数据。Archive引擎压缩数据,节省存储空间,但写入性能较低,适合只写或很少读取的场景 |
| CSV | 将数据存储为CSV文件格式,适合与外部应用程序进行数据交换。CSV引擎不支持索引和复杂的查询操作,主要用于数据导入和导出 |
文件存储层
该层负责将数据库的数据和日志存储在文件磁盘上,并完成与存储引擎的交互,是文件的物理存储层。主要包含日志文件、数据文件、配置文件、pid文件、socket文件等。
一条SQL的执行流程
根据MySQL的体系结构,SQL的执行主要经过三层:
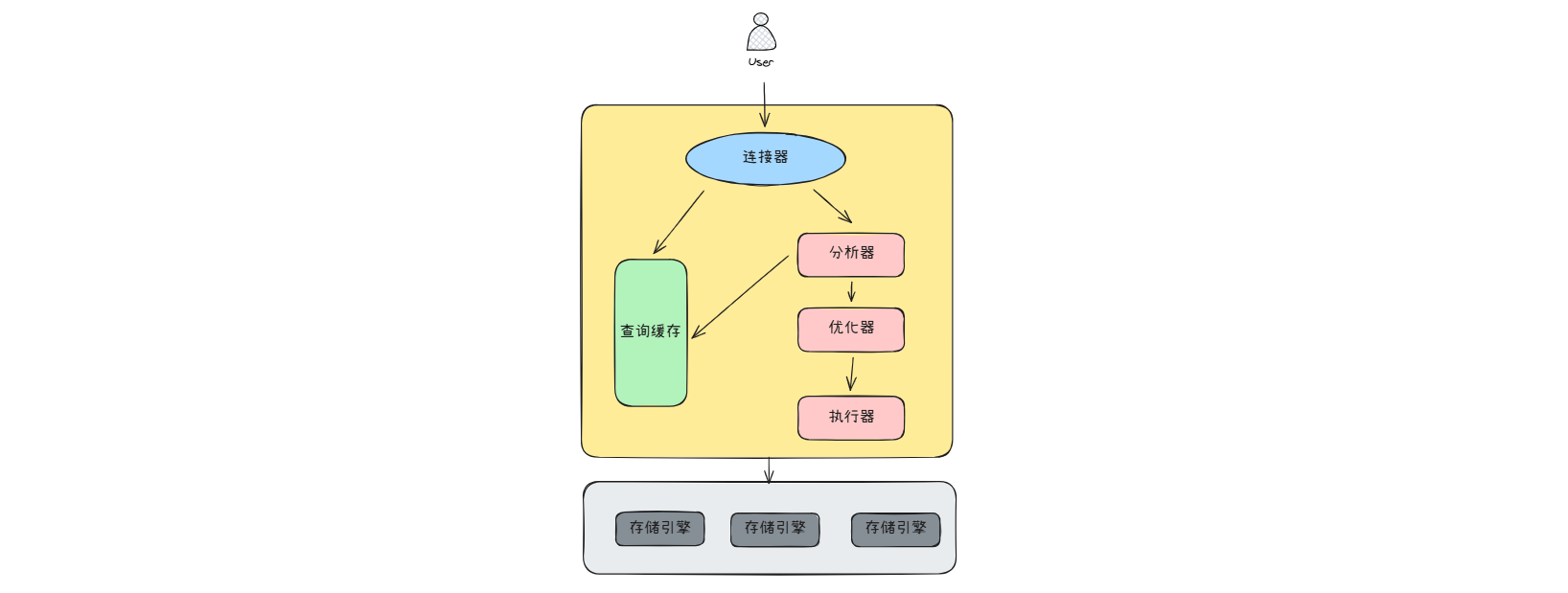
建立连接 & 权限校验
当客户端发起SQL请求时,MySQL首先在连接层处理:
- 连接管理:分配一个线程(或从连接池复用)处理该连接;
- 身份认证:验证用户名、密码、IP白名单;
- 权限检查:确认当前用户是否有权限操作目标数据库/表;
- 会话初始化:设置会话变量(如字符集、隔离级别等);
解析、优化、执行
查询解析
- 词法分析:把SQL字符串拆成一个个的Token,例如SELECT、FROM、WHERE等;
- 语法分析:构建语法树,检查是否符合SQL语法规则;
- 语义分析:验证表是否存在、列名是否正确、权限是否足够;
查询预处理
- 展开视图(如果涉及到View等)
- 检查外键约束
- 常量表达式提前计算(例如,Where 1=1 )
- 重写子查询(如将某些子查询优化为JOIN)
查询优化器
查询优化器主要要做两件事情:逻辑优化和物理优化
逻辑优化:
- 谓词下推(将Where条件尽量提前执行)
- 子查询消除
- 常量传播,等价谓词重写等
物理优化:
- 选择访问路径:全表扫描或者索引扫描
- 选择索引:哪个索引最高效
- 选择JOIN顺序,表连接的先后顺序
- 选择JOIN类型,Hash JOIN或Nested Loop