
InnoDB的核心架构
InnoDB存储引擎的体系架构
以下是官网中InnoDB的整体架构:
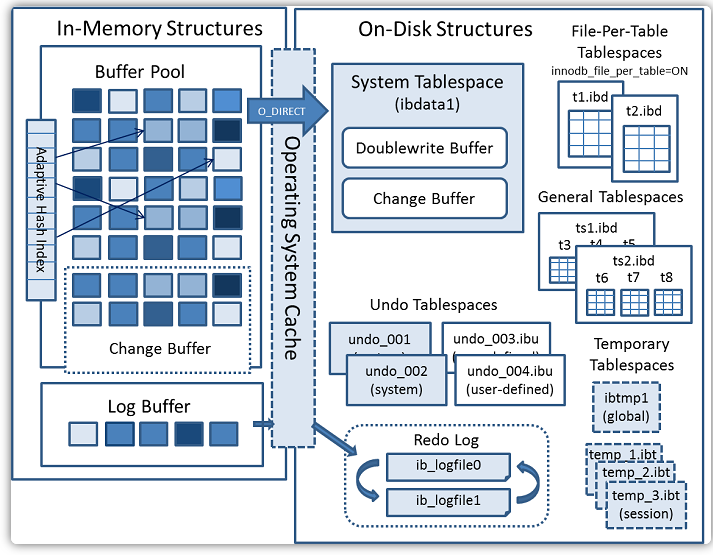
整体分为三个区域:内存、磁盘和后台线程。
InnoDB的逻辑存储架构
表空间(TableSpace)
InnoDB逻辑存储的最高层,所有数据(表、索引等)都存放在表空间中。常见类型包括:
- 系统表空间(system TableSpace)
- 独立表空间(File-Per-Table TableSpace)
- 通用表空间(General TableSpace)
- Undo 表空间
- 临时表空间
自MySQL 8.0起默认启动innodb_file_per_table,每张表拥有独立的.ibd文件,便于空间回收与隔离管理。系统表空间可容纳数据字典、双写缓冲、变更缓冲及用户表数据(取决于配置)。
段(Segment)
表空间的逻辑分区,用于管理同类页的集合。InnoDB为索引维护两类段:
- 叶子节点段(数据段)
- 非叶子节点段(索引段)
- Rollback段(与事务相关)
区(Extent)
连续的也组成的基本分配单元,默认大小为1MB。在默认16KB页配置下,每个区包含64个连续的页。
InnoDB通常以区为单位进行空间预分配,以减少碎片并提升顺序I/O效率。
页(Page)
InnoDB磁盘管理的最小单位,默认16KB(可通过innodb_page_size设置为4KB、8KB或16KB)。页是读写与缓存的基本粒度,常见页类型包括:
- 数据页(B-Tree Node)
- Undo 页
- 系统页
- Insert Buffer
- BLOB页
行(Row)
页内按照行存储记录,InnoDB为每行维护隐藏字段以支持事务一致性;
行记录支持多种格式:
- Redundant
- Compact
- Dynamic
- Compressed
其中Dynamic为MySQL 8.0默认的行格式,更适合包含BLOB/TEXT大字段场景。
InnoDB的内存架构
InnoDB的内存架构中最核心的内容就是各种类型的缓冲池:Buffer Pool(内存缓冲池)、Change Buffer、Log Buffer和自适应哈希索引。
Buffer Pool(缓冲池)
缓冲池是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据。若缓冲池中没有数据,则从磁盘加载并缓存,然后再以一定的频率刷新到磁盘,从而减少磁盘I/O。
缓冲池以Page为单位,底层采用链表数据结构管理Page,根据状态可以将Page分为三种类型:
- free page:空心页;
- clean page:被使用过的page,但是数据没有被修改过;
- dirty page:脏页,被使用过的page,其中数据与磁盘上的数据产生了不一致;
Change Buffer(更改缓冲区)
Change Buffer的主要作用是加速对非唯一二级索引的写操作,通过减少磁盘I/O来显著提升数据库的写性能。
Change Buffer主要缓冲:
- INSERT:缓冲新索引条目的插入;
- DELETE MARKING:缓冲对索引条件的删除标记(这是InnoDB实现MVVC的删除方式);
- PURGE:缓冲当不再有事务需要旧版本数据时的物理删除;
Change Buffer充当了一个“延迟写入”或“合并写入”的缓存。
缓存变更
当需要更新一个非唯一二级索引页,而该页又不在Buffer Pool中时,InnoDB并不会立即去磁盘读取它。相反,它将这次变更信息(如要插入的索引条目、要标记删除的条目等)记录到Change Buffer这个特殊的内存区域中;
后续合并
当未来某个时刻(例如,有查询需要用到这个索引,或系统空闲时),这个索引页最终被磁盘读取到Buffer Pool中。此时,Change Buffer中记录的关于这个页的所有变更,会被合并到刚刚加载进来的索引页上。这样,这个索引页在内存中就变成了最新的状态;
刷回磁盘
最终,这个在Buffer Pool中被更新过的脏页会被后台线程刷新回磁盘。
通过这种方式,将多次昂贵的随机磁盘读+随机磁盘写,转换为了一次磁盘读(将页加载到内存)和一次顺序的变更应用(在内存中合并),最后再一次性刷盘。这极大减少了磁盘的随机I/O次数。
自适应哈希索引
自适应哈希索引是InnoDB存储引擎内部一种自动化、自动优化的索引结构。它不是由用户手动创建的,而是InnoDB存储引擎根据实际的查询模式,自动在内存中为某些热点数据构建的哈希索引。
它的核心目标是:将频繁的 B+Tree 索引查询路径,转换为更快的哈希查询,从而大幅度降低查询延迟。
InnoDB会持续监控表上各个索引的查找模式,如果它发现某个索引页被以相同的方式非常频繁的访问,它就会认为这个页是热点页。
对于识别出的热点页,InnoDB会在内存中自动为其构建一个哈希索引。
- 这个哈希索引的Key是原本的索引键值的哈希值;
- 这个哈希索引得到Value是执行Buffer Pool中对应数据行记录的直接指针;
当下一次相同的查询来到时,会先检查自使用哈希索引(AHI),它计算查询条件的哈希值,然后直接在自适应哈希索引中查找。如果找到,就直接通过指针访问数据行,完全绕过了 B+Tree 的遍历过程。
自适应哈希索引是基于哈希表的,所以只能对等值查询有效,对于范围查询无效。自适应哈希索引在是在内存中建立的,所以会占用一部分的内存,如果系统内存非常紧张,可能需要关闭自适应哈希索引。同时,当发生DML操作时,InnoDB不仅需要维护 B+Tree 还需要维护自适应哈希索引,这会带来一定的开销。所以,在写密集型场景下,自适应哈希索引可能成为负担。
自适应哈希索引需要能识别出热点的查询,如果查询的模式非常随机,那么自适应哈希索引的构建和维护成本可能高于其带来的收益。
Log Buffer(日志缓冲区)
Log Buffer 是一块内存区域,用于在事务提交时,临时缓存要写入重做日志(Redo Log)的数据,目的是将多次分散的磁盘写操作合并成更少次的顺序写操作,从而极大提升数据库的写性能。
Log Buffer 的工作流程:
- 事务提交:当一个事务提交时,它所产生的所有重做日志(Redo Log)记录并不会直接写入磁盘的重做日志文件。
- 写入内存缓冲区:这些日志记录首先被非常快速地拷贝到Log Buffer这个内存区域。这是一个内存操作,速度极快;
- 刷盘时机:Log Buffer 中的内容并不会一直在内存中放着,InnoDBDB会在以下时机将其刷新到磁盘的Redo Log日志文件中。
- Log Buffer空间不足时:当写入的日志量超过Log Buffer 大小的一半左右;
- 事务提交时:这是最关键的时机,但其行为由关键参数
innodb_flush_log_at_trx_commit控制; - 后台定时花心:大约每秒一次,一个后台线程会刷新Log Buffer;
- 检查点:在进行检查点操作时,需要确保某些日志被持久化;
- 服务器空闲时;
innodb_flush_log_at_trx_commit参数的配置与含义:
- 1(默认):每次事务提交,都将Log Buffer中的日志写入OS缓冲区,并且立即调用fsync() 将其刷新到磁盘;
- 2:每次事务提交时,将日志写入OS缓冲区,但每秒才调用 fsync() 将OS缓冲区中的内容刷到磁盘;
- 0:每秒一次将Log Buffer中的日志写入OS磁盘缓冲区,事务提交时不作任何操作;
后台线程
Master Thread
Master Thread是InnoDB最核心的后台线程,它主要负责:
- 刷脏页:定期将Buffer Pool中的脏页(修改过但未写回磁盘的数据页)刷新到磁盘。在早期版本中这是主要工作,现在很多工作已经卸载给 Page Cleaner Thread。
- 合并Change Buffer:定期将Change Buffer中的变更(针对非唯一二级索引的修改)合并到真正的索引中。
- Undo Log回收:触发 Purge Thread 工作;
- 检查点:在Redo Log文件写满或定期触发时,推进LSN并管理日志空间的循环使用。
Master Thread以循环的方式工作,主要包含为每秒一次和每十秒一次的循环操作;
IO Thread(输入/输出线程)
专门处理异步IO请求的工作线程组,极大地提升了IO吞吐量。它主要负责:
- innodb_read_io_threads:负责读操作。当需要将数据页从磁盘读入Buffer Poll时,由这些线程处理;
- innodb_write_io_threads:负责写操作。当需要将脏页或日志刷新到磁盘时,由这些线程处理;
- Log IO Thread:专门处理Redo Log的写入;
Purge Thread(清理线程)
它负责清理MVCC中过期的数据,主要包含:
- 过期的Undo 日志:当事务提交后,该事务产生的Undo Log就不再被其它活跃的事务需要。Purge Thread 会将这些旧的Undo Log记录标记为可回收空间并最终清除。
- 物理删除旧行版本:执行最终的DELTE操作,物理删除被标记为删除的行。
Page Cleaner Thread(页面清理线程)
专门负责刷新脏页,从MySQL 5.6版本引入,专门接管Master Thread中最繁重的刷脏页任务。它的主要工作为:
- 计算最优刷脏策略:根据系统负载、Redo Log生成速度等因素,智能地决定刷脏页的频率和数量,避免在系统繁忙时突然进行大量IO操作导致性能波动。
- 异步刷脏:将脏页刷新工作卸载到独立线程,使Master Thread可以更专注于调度,从而提升整体性能和稳定性;
这是InnoDB性能演进中的一个重要改建,使得刷脏页更加平滑和高效。
Redo Log Thread(重做日志线程)
专门负责将Log Buffer中的内容写入到Redo Log文件中,主要工作:
- 根据
innnodb_flush_log_at_trx_commit参数的设置,在事务提交时或定时将Log Buffer中的日志写入磁盘; - 执行Log Buffer的刷盘(fsync)操作;
在更早的版本中,Log Buffer的写入由Master Thread或用户线程完成。将其独立出来,避免了用户线程在提交时直接以等待慢速的磁盘IO,提高了并发处理能力。
InnoDB存储引擎的核心特性
插入缓冲
插入缓冲是InnoDB一个非常核心且早期的关键特性,实际上是Change Buffer的前身。
早期版本(MySQL 5.5之前)为Insert Buffer,最初只支持缓冲Insert操作所导致的非唯一二级索引的变更,后来增加了对DELETE操作的部分支持,但功能相对单一。
现代版本(MySQL 5.5及之后)为Change Buffer,作为Insert Buffer的增强版,支持缓冲更多的操作类型:INSERT、DELTE MARKING和PURGE。
Insert Buffer可以将多次IO转换为少量的顺序IO,这是最核心的优势。它将对二级索引页的多次离散、随机更新,在内存中合并,最后一次性顺序地写回磁盘。性能提升巨大,尤其对于写密集型应用。
Insert Buffer仅支持非唯一二级索引引起的变更,这是因为唯一索引要求检查唯一性约束。要检查INSERT的值是否唯一,必须将对应的索引页读到内存中查看是否已经存在,无法避免读磁盘。因为Insert Buffer避免随机读的前提就不存在了。而非唯一索引没有这个约束,可以安全地延迟更新。
两次写
在InnoDB中页默认大小为16KB,但是操作系统和硬盘块的大小通常是4KB。这也就意味着,在InnoDB中一个页对应的是磁盘上的4个页。
两次写主要解决的问题是:InnoDB在将一个脏页刷新回磁盘的时候,需要完成硬盘上4个页的写入。如果只写入了部分的页,系统突然崩溃(如断点),将会导致数据混乱。
两次写的机制需要借助DoubleWrite Buffer:在共享表空间中开辟的连续存储,大小约为2MB;两次写的步骤:
- 顺序写
- 当刷新脏页时,InnoDB不是直接写到数据文件的目标位置,而是顺序地将这批脏页的副本写入到DoubleWrite Buffer在内存中的区域;
- 然后,将整个DoubleWrite Buffer顺序地、连续地写入磁盘上共享表空间中的固定位置;
- 离散写
- 在确保DoubleWrite Buffer已经安全持久化到磁盘后。
- InnoDB再将这些脏页逐个地、离散地写入到数据文件中它们真正应该去的位置。
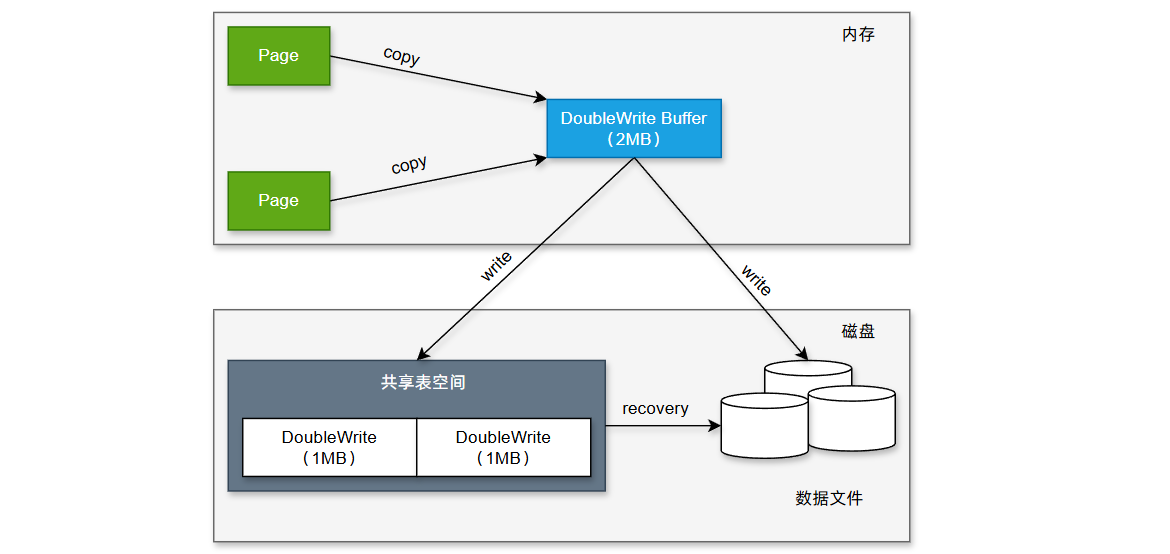
如果系统在二次写过程中崩溃,数据文件中的页可能是损坏的,但是DoubleWrite Buffer中保存着这个页的一个完整的副本。在崩溃恢复期间,InnoDB会检查数据文件中的页是否损坏,如果发现损坏,直接从DoubleWrite Buffer中把完整的副本拷贝过来覆盖损坏的页。一旦页被修复成完整的物理状态,就可以正常使用Redo Log来重放日志,恢复到最后一次提交的逻辑状态。
两次写解决的是部分页更新的问题,产生这个问题的原因是大多数的存储设备都不保证大于4KB写入的原子性,而InnoDB的页大小是操作系统的4个页,所以在InnoDB中对于页的更新无法通过操作系统来保证它的原子性。
异步IO
异步IO是指线程在发出磁盘读写请求后可以立即继续执行,不必等待该IO完成;当一批请求都发出后,再统一等待完成事件。与同步IO相比,它显著减少了线程阻塞与等待时间。
InnoDB在Linux/Windows上可使用内核级 Native AIO,早期版本通过引擎内模拟实现,Native AIO在Linux上默认开启。
在InnoDB中异步IO的使用场景:
- 读取预读:顺序扫描或索引扫描触发的预读全部通过AIO发起,提前把后续可能需要的页装入Buffer Pool中,降低查询等待;
- 脏页刷写:将Buffer Pool中脏页写回数据文件由AIO完成,避免前台线程阻塞,提升写吞吐与响应平滑度;
- 日志写入:为保证WAL严格有序与持久性,InnoDB对重做日志文件不使用AIO,由专门的日志线程以同步方式确保落盘顺序与一致性。
InnoDB存储引擎中的日志文件
WAL(Write-Ahead Logging)
WAL的核心原则非常简单却极其强大:在数据页的修改被刷到磁盘之前,必须先确保描述这些修改的日志记录已经持久化在磁盘上。
通俗来讲,就是先写日志,再写数据。日志落盘,事务才算真正安全。
WAL主要解决的两大问题:
随机IO
问题:数据页在磁盘上的存储是离散的,每次提交事务都直接写数据页,会导致大量的随机磁盘写入,性能极差;
解决方案:将事务对数据页多种随机修改,转换为对日志文件的顺序追加写入。顺序IO效率比随机IO高出几个数量级;
崩溃恢复与持久性保证
问题:如果事务提交后,修改的数据页还留存在Buffer Pool中,此时数据库崩溃,数据就会丢失;
解决方案:事务提交时,只要求将Redo Log刷盘。因为日志是顺序追加的,这个操作非常快。一旦日志落盘,即使数据页没有写回磁盘,在崩溃后也能通过Redo Log来恢复数据,从而保证了事务的持久性。
WAL的主要工作流程:
修改内存页
当一个事务修改数据时(如UPDATE),InnoDB首先在内存的Buffer Pool中找到对应的数据页。如果不在内存,则从磁盘读取。
生成Redo Log
InnoDB不会立即将脏页刷新到磁盘上,相反,它会将如何在磁盘上重现这个修改的信息记录成一条Redo Log记录(这个日志首先会被写入到Log Buffer中)。
事务提交与日志刷盘
当事务提交时,InnoDB根据
innodb_flush_log_at_trx_commit参数的设置,决定Log Buffer的刷盘策略。当设置为1(最安全)时,InnoDB会确保该事务产生的所有Redo Log记录被强制刷入磁盘的Redo Log文件。这是一个相对快速的顺序写操作。
返回成功
一旦Redo Log被确认写入磁盘,数据库就可以向客户端返回事务提交成功,此时事物的持久性已经得到了保证;
异步刷新脏页
脏页被刷新回数据文件的操作,是由后台线程在某个合适的时机异步完成的。
二进制日志文件(Bin log)
二进制日志文件就是常说的binlog,但是它不是InnoDB的日志文件,而是MySQL Serever层的日志文件。这一点需要与redo log和undo log区分开来,redo log和undo log是InnoDB存储引擎中的日志,它是属于存储引擎层的日志文件。
binlog主要是用来记录对MySQL数据更新或潜在发生更新的SQL语句,记录了所有的DDL和DML(除了查询语句外),并以事务的形式保存在磁盘中,还包含语句所执行的消耗时间,MySQL的binlog是事务安全型的。
binlog的主要作用:
- 恢复:某些数据的恢复需要二进制额日志,例如,在一个数据库全备文件恢复后,用户可以通过二进制日志进行point-in-time的恢复;
- 复制:其原理与恢复类似,通过复制和执行二进制日志使一台远程的MySQL数据库与一台MySQL数据库进行实时同步;
- 审计:用户可以通过二进制日志信息来进行审计,判断是否有对数据库进行注入的攻击;
binlog的基础配置:
[mysqld]
# 设置当前MySQL实例在复制架构中的唯一标识符
server-id=1
# 启用二进制日志功能,并设置二进制日志文件的基本名称
log-bin=mysql-bin
# 二进制日志的记录格式
binlog_format=ROW
# 设置二进制日志的同步策略,1表示安全级别最高的安全设置
sync_binlog=1
# 设置单个二进制日志文件的最大大小
max_binlog_size=1Gbinlog的格式:
STATEMENT:记录原始的SQL语句
优点:日志文件小;
缺点:可能不安全,对于Now()、RAND()等非确定性函数,在主从库上得到不同的结果,导致数据不一致;
ROW:记录每一行数据被修改后的实际结果
优点:最安全,能保证主从数据绝对的一致性
缺点:日志文件可能非常大(例如,一个UPDATE语句更新了10万行,在STATEMENT模式下只记录一条SQL,而在ROW模式下会记录10万行变化);
MIXED:MySQL自行判断,多数情况下使用STATEMENT,在不安全时切换为ROW。
在讲到binlog的刷盘策略的之前需要知道的是,对于MySQL而言,它通常是将binlog的内容写入到操作系统的缓存(Page Cache)中,然后由操作系统调用fsync()方法来将缓存中的内容刷新到磁盘上。
binlog的刷盘策略:
- sync_binlog = 0:将日志写入到操作系统缓存后就返回成功,由操作系统后台线程决定何时刷盘(可能延迟几秒到几十秒),宕机可能丢失大量日志。
- sync_binlog = N:每N次事务提交后,立即调用fsync()方法刷盘;
- sync_binlog = 1:每次事务提交后,调用一次fsync()刷盘;
通常而言,对于binlog的刷盘策略都会设置为1,它每次提交事务都会调用fsync()方法。fsync()是一个阻塞调用,它会要求操作系统立即将执行文件的所有脏页从Page Cache写入物理磁盘的持久存储介质。MySQL线程会在此等待,直到fsync()操作完成并返回成功,只有在收到fsync()的成功返回后,MySQL才会向客户端返回事务提交出成功。
重做日志(redo log)
Redo Log是物理日志,它记录的是数据页的物理变化,比如在哪个页的多少偏移量写入了什么数据等。
InnoDB的Redo Log在物理上由一组文件实现,通常命名为 ib_logfile0 和 ib_logfile1。当事务提交时,必须先将事务的所有日志写入到重做日志文件进行持久化,待事务的COMMIT操作完成才算完成。在InnoDB存储引擎中,redo log是用来保证事务的持久性的,而undo log用来帮助事务回滚以及MVCC的功能。
redo log刷盘完整的流程:当有事务提交时,会生成redo log,然后将其写入到Log Buffer的Redo Log Buffer中。然后会将Redo Log Buffer中的内容写入到文件系统的缓存中,最终需要调用fsync()方法将文件系统的缓存刷新到具体的文件中。
redolog的刷盘策略:
- innodb_flush_log_at_trx_commit = 1(默认值),表示事务提交时,必须调用fsync()方法将redo log刷新到磁盘上;
- innodb_flush_log_at_trx_commit = 0,表示事务提交时不进行人任何操作,由Master Thread来将redo log buffer中的内容写入刷新到磁盘上;
- innodb_flush_log_at_trx_commit = 2,表示事务提交时,将redo log写入操作系统的文件缓冲中,就返回成功;
redo log 与 bin log 的二阶段提交
二阶段提交的工作流程:
Prepare阶段
- 写Redo Log:InnoDB将事务的Redo Log 写入 Log Buffer,并将日志记录的状态标记为PREPARE;
- 刷盘,根据innodb_flush_log_at_trx_commit的设置,将Redo Log刷新到磁盘上;
- 此时事务已经准备好提交,但尚未最终生效;
Commit阶段
- 写binlog:MySQL Server将事务的bin log写入 bin log Buffer中,然后再写入磁盘上的Binlog文件缓存;
- 刷盘:根据 sync_binlog 设置,可能调用fsync()将Binlog强制刷入物理磁盘;
- 写Redo Log Commit标记:Binlog写入成功后,InnoDB立即写一条Redo Log记录,将事务的状态标记为Commit;
- 刷盘:将包含Commit标记的Redo Log刷盘;
- 给客户端返回事务提交成功;
二阶段工作流程的时序图:

当有了redo log 和 bin log的二阶段提交后,可以保证bin log和redo log的一致性。对照上面的时序图:
- 如果在prepare阶段的时候,MySQL发生了宕机,那么在根据redo log恢复的时候,针对这个事务,在bin log中不存在对应的记录,所以恢复的时候可以直接丢弃掉。
- 如果在Commit阶段的时候,将事务标记为Commit状态时,MySQL发生了宕机,针对这个事务,在bin log中是存在对应的记录的,所以恢复的时候只需要提交这个事务就可以了。
所以MySQL恢复的时候通过重放redo log,它遵循的原则是:在bin log中存在的事务,在数据文件中一定被提交了;bin log中不存在的事务,在数据文件中一定会被回滚。
提示
在我个人的理解上来看,redo log是InnoDB为了保证高性能事务的核心文件,但是bin log因为是MySQL的Server层的日志文件,InnoDB必须要保证bin log的数据与redo log的数据是一致的,否则在主从复制的时候时候从库的就会出现主从不一致的问题,所以bin log在某个层面上来讲成为了InnoDB高并发事务特性的一种负担。
回滚日志(undo log)
undo log 是事务原子性的保证,在事务更新数据之前需要先写入一个Undo log。数据事务开始之前,会将要修改的记录放到Undo log里,当事务回滚时或者数据库崩溃时,可以利用Undo log撤销未提交事务对数据库产生的影响。MySQL把这些为了回滚而记录的这些内容称之为撤销日志或回滚日志。
因为select语句不会对数据产生影响,所以select不需要记录相应的undo log
Undo Log的存储结构
InnoDB对Undo Log的管理采用段的方式,也就是回滚段(Rollback Segment)。每个回滚段记录了1024个Undo Log Segment,而在每个Undo Log Segment段中进行Undo页的申请。
在InnoDB 1.1版本之前(不包括1.1版本),只有一个Rollback Segment,因此支持同时在线的事务限制为1024。虽然绝大多数的应用来说已经够用,但是在1.1版本开始InnoDB支持最大128个Rollback Segment,所以同时在线事务的限制提升到了 128 \times 1024 = 131072 个。
Rollback Segment采用的时循环覆盖的写入模式,当一个事务开始的时候会指定一个Rollback Segment,如果在事务的过程中数据发生了变化,就会将原始数据复制一份到Rollback Segment中。
Rollback Segment中的数据分类
- 未提交的回滚数据(uncommitted undo information):该数据所关联的事务并未提交,用于实现读一致性,所以该数据不能被其它事务的数据覆盖;
- 已经提交但未过期的回滚数据(committed undo information):该数据关联的事务已经提交,但是仍收到undo retention参数的保持时间的影响;
- 已过期的回滚数据(expired undo information):事务已经提交,而且数据保存时间已经超过了undo retention参数指定的时间,属于已过期的数据。当回滚段满了之后,会优先覆盖事务已经提交并过期的回滚数据。
undo log的存储机制
undo log存储在Undo TableSpace中(默认是系统表空间ibdata1,MySQL 5.6+支持独立Undo 表空间)。每个事务在执行DML(INSERT/UPDATE/DELETE)时,会生成对应的undo log记录。
undo log记录包含:
- 事务ID(trx_id)
- 数据修改前的旧值
- 指向下一个undo log记录的指针(形成链表)
- 表空间ID、页号、偏移量等定位信息
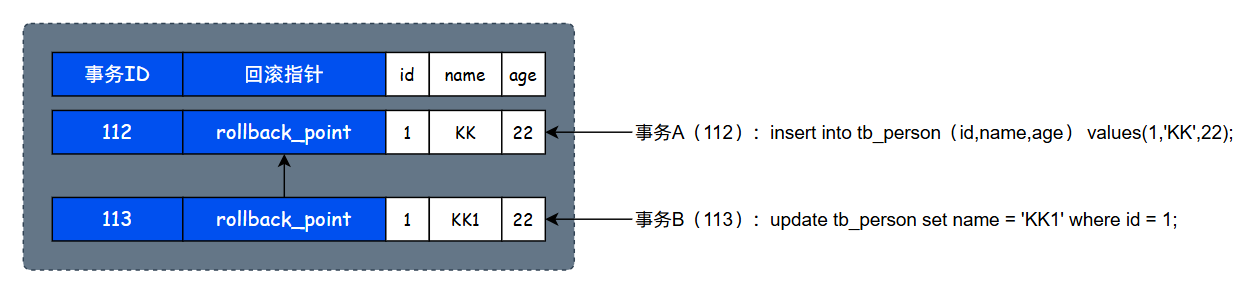
undo log分为两个类型:
- insert undo log:由INSERT语句产生,仅用于事务回滚。事务提交后可立即删除。
- update undo log:由UPDATE和DELETE语句产生,不仅用于回滚,还用于MVCC。只有当没有事务再需要旧版本数据时才可以被删除。
当事务提交后,undo log并不会立即删除,而是标记为“可重用”。当没有活跃事务再需要改版本的数据时(即MVCC不再引用),Undo Log才会被清理(Purge线程负责清理)。
当一个事务提交后,其undo log是否可重用,取决于:
- 没有活跃事务再需要改版本的数据(MVCC不再引用);
- Purge线程处理完成;
- Undo Page已满或部分空闲;
当一个事务提交后,InnoDB会将该事务的undo log标记为“已提交”,但是并不会立即删除该undo log,它会等待purge线程来处理。purge线程扫描到这个undo log的时候会检查这个undo log记录的事务是否被MVCC读视图引用,如果无引用,则标记该记录为“可重用”。重用分为三种情况:
- 页级重用:如果整个页可重用,将其加入“空闲列表”,供新事物分配;
- 记录级重用:如果页中部分空间空闲,InnoDB会“紧凑化”该页,将空闲空间合并,供新的undo log记录使用;
- 段级重用:如果整个undo segment空闲,可被新事务复用;
undo log的工作流程
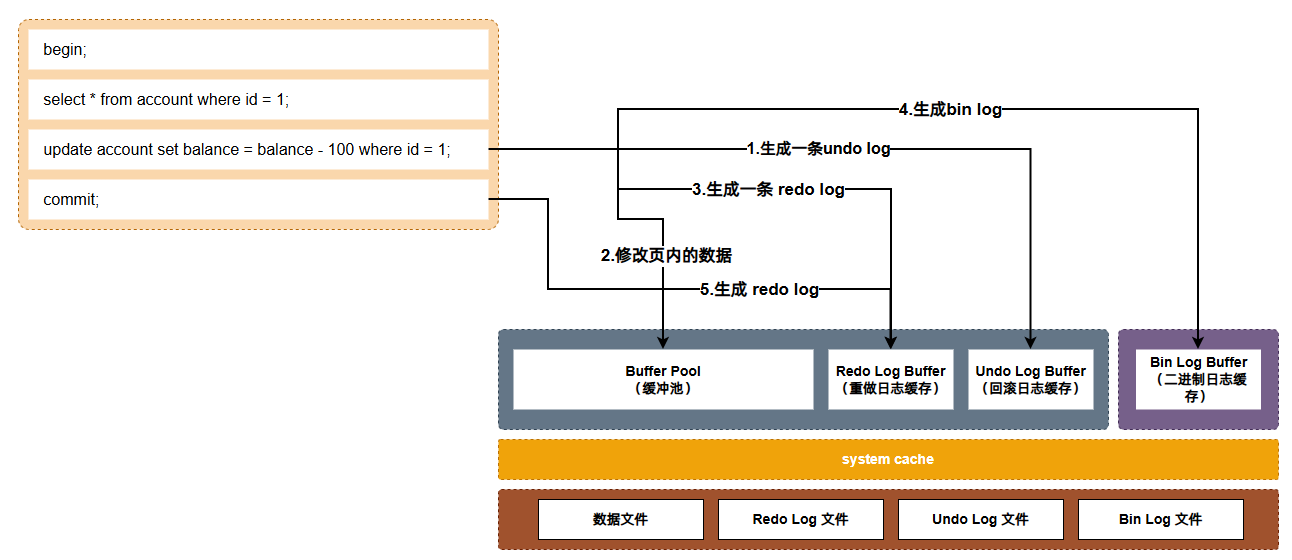
当如下事务执行时:
Plain Text BEGIN; UPDATE account SET balance = balance - 100 WHERE id = 1; COMMIT;它的undo log、redo log和bin log之间的写入流程为:
- 当执行事务中的第一条修改数据的SQL时,会生成一个undo log;
- 执行SQL后会修改Buffer Pool中对应的页的数据(该页变成脏页,后续由Page Cleaner Thread进行刷盘);
- Buffer Pool中的内容修改完后,会生成一条redo log,此时会根据
innodb_flush_log_at_trx_commit参数配置的策略来对redo log进行刷盘; - 生成一条bin log,会根据
sync_binlog参数配置的策略来对bin log进行刷盘; - 再次生成一条redo log,该redo log的作用是将事务标记为commit状态,此时依旧是根据
innodb_flush_log_at_trx_commit参数配置的策略来对redo log进行刷盘;
简单理解,就是第二次redo log的提交主要为了保证bin log一定提交完成了
一个事务执行的过程中undo log、redo log和bin log之间的写入关系:
InnoDB存储引擎的事务特性
在MySQL中,事务的特性是由存储引擎来保证的,例如MyISAM就是不支持事务的,InnoDB是支持事务的。InnoDB的事务特性主要是由redo log和undo log来实现的,其中redo log实现的是事务的持久性,undo log保证的是事务的原子性。
事务的特性
原子性(Atomicity)
一个事务中所有操作是一个整体,它们要么全部成功完成,要么如果其中任何一步失败,所有已执行的操作都会被撤销,事务不能执行一部分。
一致性(Consistency)
一致性是指数据必须满足预先定义好的规则,例如唯一性约束、外键约束、数据类型检查等。事务的执行结果必须保证数据库依然遵守这些规则。
隔离性(Isolation)
当多个事务同时访问和修改数据库时,隔离性确保每个事务感觉不到有其它事务在同时执行。也就是说,一个事务在提交之前,其中间状态对其他事务是不可见的。
持久性(Durability)
即使系统发生任何故障,已提交事务对数据库的修改也不会丢失。数据被持久化地保存到存储设备中。
事务的隔离级别
事务的隔离性理性情况下要求所有事务完全串行执行,但这会极大降低数据库的并发性能。为了在性能和数据准确性之间取得平衡,数据库标准定义了不同的隔离级别,允许开发者根据业务场景,在可接受的范围内放松一些隔离性的要求,从而换取更高的并发能力。
对应四种不同的读现象:
- 脏读:一个事务读到了另一个未提交事务修改的数据;
- 不可重复读:在同一个事务内,两次读取同一行数据,得到的结果不一致。这是因为在两次读取之间,有另一个事务修改并提交了这行数据;
- 幻读:在同一个事务内,两次执行相同的条件查询,得到的记录行数不一致。这是因为在两次查询之间,有另一个事务插入或删除了符合该查询条件的记录并提交了;
SQL标准定义了四种隔离级别,从低到高,隔离性越来越强,但并发性能依次降低:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 描述 |
|---|---|---|---|---|
| 读未提交(Read UnCommitted) | 是 | 是 | 是 | 最低级别,性能最好,但数据一致性风险最高 |
| 读已提交(Read Committed) | 否 | 是 | 是 | Oracle、PostgreSQL、SQL Server的默认级别 |
| 可重复度(Read Repeatable) | 否 | 否 | 是 | MySQL的InnoDB引擎默认级别,保证在同一事务内两次查询的结果一致 |
| 串行化(Serializable) | 否 | 否 | 否 | 最高级别,完全串行化执行,隔离性最强,但性能最差 |
如何选择隔离级别?
- 大多数情况:使用数据库的默认级别(读已提交或可重复读)通常是一个安全的选择;
- 对数据一致性要求极高,且可以接受性能损失:考虑使用串行化(如金融核心交易);
- 只追求最高性能,对脏读不敏感:才可以考虑读未提交;
- 需要平衡:通常需要再应用层通过乐观锁、悲观锁或重试机制来补充处理在“读已提交”或“可重复读”级别下可能出现的一致性问题。
多版本并发控制(MVCC)
在InnoDB中最重要的RC和RR隔离级别,Read UnCommitted和Serializable在常见的业务场景下一般都是不会选择的。对于RC和RR而言,它们特点是由MVCC(Multi Version Concurrency Control)机制来保证的,也就是说MVCC只在RC和RR级别下工作。
MVCC的基本理念是:不为数据加锁,而是为数据创建多个版本。
当一行数据被修改时,数据库不会直接覆盖原有的数据,而是创建该数据的一个新版本。这样,读操作可以继续访问旧版本的数据,而写操作可以创建新版本,从而实现了读、写操作之间的非阻塞并发。
在没有MVCC的时候只能使用传统锁机制:
- 读-写冲突:一个事务在读数据时,另一个事务不允许修改改数据(需要加共享锁);
- 写-写冲突:一个事务在写数据时,其他事务不能读数据,也不能写该数据(需要加排他锁);
MVCC解决了这个问题:读操作永远不需要等待写操作,写操作页几乎不需要等待读操作;
MVCC实现最核心的媒介就是undo log,正是因为undo log的存在,才会MVCC机制提供了依据。
MVCC下的读操作与写操作
读操作
当一个事务指定读取操作时,它会使用快照读取。快照读取时基于事务开始时数据库中的状态创建的,因此事务不会读取其它事务尚未提交的修改。
对于读操作,事务会查询符合条件的数据行,并选择符合其事务开始时间的数据版本进行读取。如果某个数据行有多个版本,事务会选择不晚于其开始时间的最新的版本,确保事务只在读取在它开始之前就已经存在的数据。
事务读取的是快照数据,因此其它并发事务对数据行的修改不会影响当前事务的读取操作。
写操作
当一个事务执行写操作时,它会生成一个新的数据版本,并将修改后的数据写入数据库。
对于写操作,事务会为要修改的数据行创建一个新的版本,并将修改后的数据写入新版本。新版本的数据会带有当前事务的版本号,以便其它事务能够正确读取相应版本的数据。原始版本的数据仍然存在,供其它事务使用快照读取,这保证了其它事务不受当前事务写操作的影响。
当前读与快照读
当前读
当前读的意思就是读取数据的最新版本,读取时概要保证其它并发事务不能修改当前记录,会对读取的记录进行加锁。
像select … lock in share mode和select ... for update、update、insert、delete这些操作都是一种当前读。
快照读
读取数据在某个时间点的一致性快照,而不是当前的最新值。
快照读是基于Read View(读视图)来实现的。
class ReadView {
// 当前活跃(未提交)的事务ID列表
trx_id_t* m_ids;
// 最小活跃事务ID
trx_id_t m_low_limit_id;
// 下一个要分配的事务ID
trx_id_t m_up_limit_id;
// 创建该ReadView的事务ID
trx_id_t m_creator_trx_id;
// ReadView创建时间点
time_t m_create_time;
};对于上述参数的理解,可以参考下图:
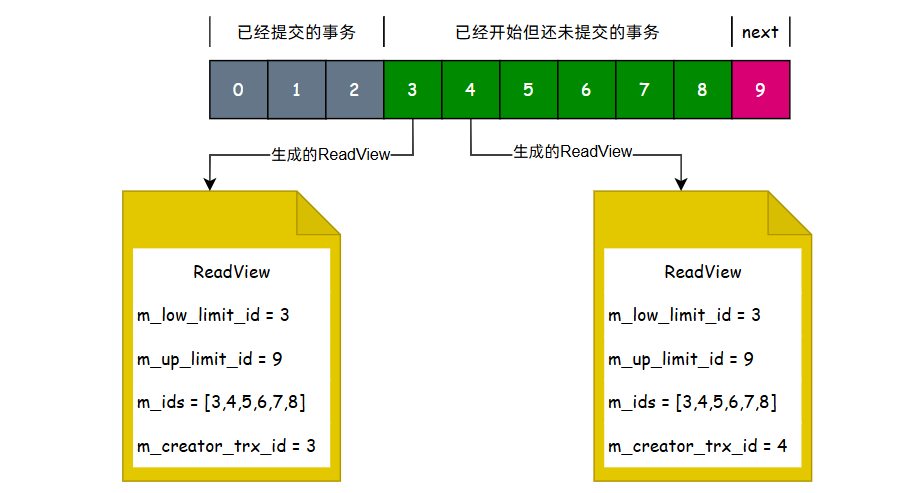
对照上图对于ReadView的可见性规则,也是可以被很容易推算出来:
- 当undo log中数据的
trx_id < m_low_limit_id表示这些数据在当前事务开启之前就已经提交了,属于当前事务的可见范围; - 当undo log中数据的
trx_id >= m_up_limit_id表示这些数据是在当前事务开启之后才开启的事务修改的,属于当前事务的不可见范围; - 当undo log中的数据
m_low_limit_id < trx_id < m_up_limit_id且trx_id in m_ids[]时,表示当前事务开启时,这些事务还处于活跃状态,所以对于它们修改的数据也是不可见的。 - 当undo log中的数据
m_low_limit_id < trx_id < m_up_limit_id且trx_id not in m_ids[],表示当前事务开启时,这些事务已经提交了,所以对于它们修改的数据是可见的。(出现这种情况是很正常的,例如trx_id = 1 的事务执行的很慢,但是 trx_id = 2 的事务执行的很快,此时最小活跃的m_low_limit_id = 1,且2不会在m_ids[]数组中)。
RC级别下利用快照解决脏读
在我们理解了快照读、当前读以及ReadView的基本内容后,其实对于RC如何解决脏读就非常容易得到方案了。
假如在RC隔离级别下,有下面三个事务,它们的执行顺序如下图所示:

此时,数据库中undo log日志中记录的版本链信息如下图所示:

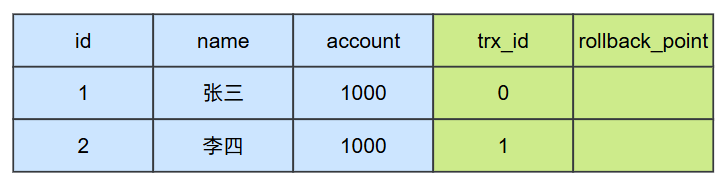
如果这个id=1记录是由trxid = 0 的事务插入进来的,那么它隐藏字段中trxid就是0,且此时trx_id = 0 的事务是已经提交的。
我们顺着时间线,来分析数据库中数据的变化:
在t1时刻,事务1和事务2同时开启;
在t2时刻,事务2修改了表中的数据,此时对于 id = 1 的数据而言,他会存在两个版本;
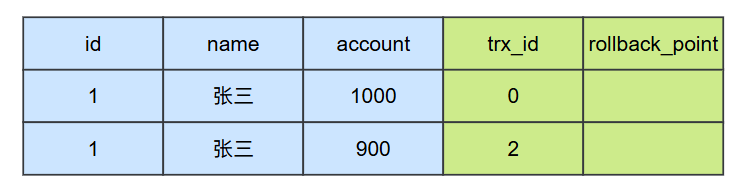
在t3时刻,事务1开始查询 id = 1的这条记录,此时会生成一个ReadView,那么这个ReadView中包含的内容为:
{
"m_low_limit_id":1,
"m_up_limit_id":3,
"m_ids":[1,2],
"m_creator_trx_id":1
}根据ReadView可见性原则分析,事务2修改的数据对于事务1修改的数据是不可见的,也就是说在t3时刻,事务1查询到的account的值仍然是1000。
在t4时刻,事务1修改了 id = 1 的这条记录,此时数据库就会存在3个版本的 id = 1的这条数据的快照。
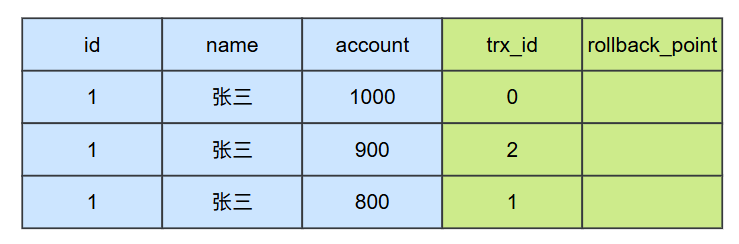
在t5时刻,事务3要查询id=1的这个记录,此时他会创建一个ReadView,此时这个ReadView的内容为:
{
"m_low_limit_id":1, // 此时事务1仍然未提交
"m_up_limit_id":4, // 此时事务3已经开启,所以下一个待分配的id为4
"m_ids":[1,3], // 此时事务2已经提交,所以它不在活跃列表中
"m_creator_trx_id":3
}对这个ReadView来进行分析,可以看到事务2修改的版本,对于事务3而言是可见的,但是事务1修改的版本对于事务3是不可见的,所以在t5时刻,事务查询到account的值就是900;
在t6时刻,事务3修改了id=1的记录,所以在数据库中它存在四个版本的数据:
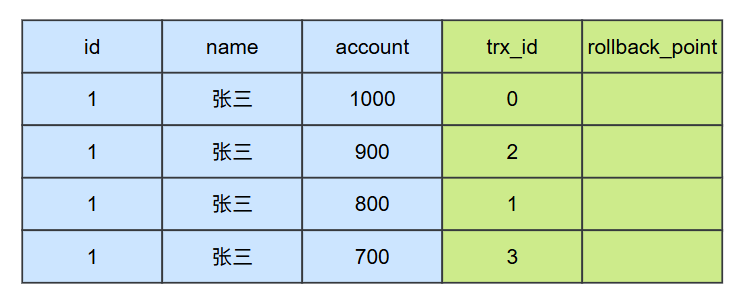
在t7时刻,事务3再次查询id=1的记录,所以他会再次生成一个ReadView,此时这个ReadView的内容为:
{
"m_low_limit_id":3,
"m_up_limit_id":4,
"m_ids":[3],
"m_creator_trx_id":3
}根据这个ReadView的内容来进行分析,事务1修改的数据对于事务3是可见的,但是它不是最新的版本的。因为事务3修改的版本是最新的,所以它读取到account的值就是700。
如果在t6时刻,事务3没有进行update操作,那么在数据库中对于id=1这条数据的最新的快照版本就应该是事务1提交的这条,那么在t7是时刻,事务3查询到的结果就是800。在这种情况下,对于事务3而言,它的两次相同查询SQL返回的account不同,也就是不可重复读的问题。
RC隔离级别在每次查询的时候都会生成一个ReadView,每次生成ReadView的时候都可以获取到最新的数据版本,所以在RC隔离级别下可以查询到其它事务提交的数据,但是同理也会造成两次读取到的结果不同,就是不可重复读的问题。
RR级别下利用快照解决不可重复读
依旧使用的是上面案例中的事务和数据,在RR级别下,它的数据流转的步骤为:
t1 ~ t4时刻与RC的流程并没有什么不同。
t5时刻,事务3开启了,此时它需要查询 id = 1 的这条数据,那么它会创建一个ReadView,此时ReadView的内容为:
{
"m_low_limit_id":1,
"m_up_limit_id":4,
"m_ids":[1,3],
"m_creator_trx_id":3
}对ReadView来进行分析,事务3可以看到的最新的版本就是事务2提交的版本,所以在t5时刻查询到的account的值就是900。
在t7时刻的时候,事务3再次查询id=1的数据,它分为两种情况来看:
在t6时刻没有执行update操作
如果在t6时刻没有执行update操作,在RR级别下不会生成新的快照,而是使用第一次创建的快照。所以对于事务3而言,它的可以看到的最新版本仍然是事务2提交的版本,所以在t7时刻查询到的account的值就是900;因此,在t5时刻和t7时刻查询到的结果是一样的,也就解决了不可重复的问题。
在t6时刻执行了update操作
如果在t6时执行了update操作,它属于当前读,那么在RR级别下就会重新生成ReadView,此时ReadView的结果为:
{
"m_low_limit_id":3,
"m_up_limit_id":4,
"m_ids":[3],
"m_creator_trx_id":3
}所以此时它可见的最新的版本就是事务3自己修改的这个版本,也就是它读取到的数据就是700;
所以在RR级别下,对于快照度而言,它每次都是使用第一次创建的快照,所以两次查询的结果是相同的。当出现当前读的时候,就会刷新快照读取到当前修改的最新的数据。
为什么说RR级别解决了部分的幻读问题?
直接说结论,如果快照读之间不存在当前读,就可以解决幻读的问题,反之就无法解决幻读的问题。
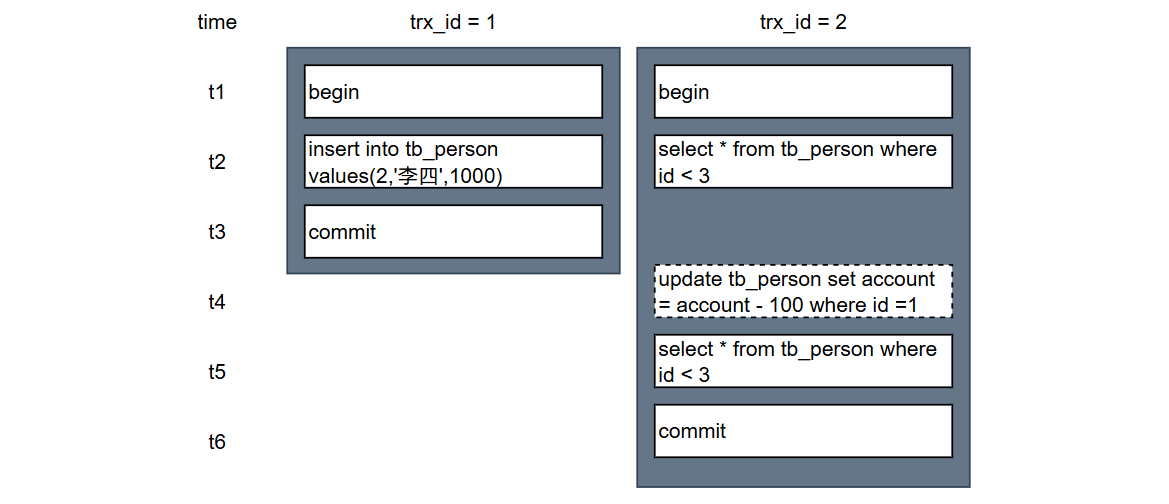
假如在RR隔离级别下,存在下面两个事务:
此时数据库中的数据版本为:

在t2时刻,对于事务3而言,它生成的ReadView的内容为:
{
"m_low_limit_id":1,
"m_up_limit_id":3,
"m_ids":[1,2],
"m_creator_trx_id":2
}所以对于事务2而言,它可见的最新的版本就是 trx_id = 0 的快照版本,所以此时查询到的数据返回的结果为1条;
在t3时刻之后,因为事务1插入了一条数据并且完成了提交,那么此时在数据库就存在两条数据:
两次快照读之间不包含当前读
如果在t4时刻事务2没有执行update语句,就是这种场景。此时它仍然是使用t2时刻创建的ReadView,那么然能读到最新的数据仍然是只有一条。因为仅管事务1已经提交了,但是在t2时刻的ReadView中它的数据仍然是不可见的。
两次快照读之间包含当前读
如果在t4时刻,事务2执行了update语句,此时会刷新ReadView,那么此时ReadView的内容为:
{
"m_low_limit_id":2,
"m_up_limit_id":3,
"m_ids":[2],
"m_creator_trx_id":2
}根据ReadView的可见性原则判断,事务1提交的数据对于事务2现在是可见的,所以在t4时刻查询的结果数量为2;
根据上面的分析可以看到在RR隔离级别下,可以解决一部分的幻读问题,但是如果两次快照读中间存在当前读的情况下,就无法解决幻读的问题。
RR隔离级别下使用间隙锁来解决幻读的问题
我们对于上面案例中的事务2进行修改:
begin;
# 添加共享锁
select * from tb_person where id < 3 for lock share mode;
update tb_person set account where id = 1;
select * from tb_person where id < 3 for lock share mode;
commit;如果将事务修改为上述的样子后,在t2时刻:
- 如果事务1的插入先执行,那么事务2的查询就会被阻塞到事务1提交之后,那么此时t2时刻查询回来的结果就是2条,同理t5时刻查询回来的结果也是2条,就不会出现幻读的问题了;
- 如果事务2的查询先执行,那么事务1的查询就会被阻塞到事务2提交之后,那么此时t2时刻查询回来的结果就是1条,同理t5时刻查询回来的结果也是1条,就不会出现幻读的问题了;
所以在RR隔离级别下要想完整的解决幻读的问题,还是需要我们显示加锁的,来保证读取和写入的顺序来达到不出现幻读的问题。
所以在RR隔离级别下,推荐的做法是:
- 读数据 + 不修改 ==> 用普通的
select(MVCC自动避免幻读); - 读数据 + 要修改 ==> 用
select ... for update(锁住范围,避免幻读); - 确保查询条件有索引 ==> 让临键锁生效,否则就会升级为表锁,将会大大降低性能;