LLM大模型概述
什么是大模型
LLM的全称是Large Lanuage Model(大语言模型),简单来说,它就是一个通过海量文本数据(如书籍、网页、代码等)训练出来的AI系统,能够理解、生成、翻译人类语言,甚至编写代码。
提示
作为一名Java开发工程师,在学习AI开发时,其实你不需要去深究复杂的算法底层(例如,Transform架构的数学推导或神经网络训练),现阶段对你而言,把LLM当成一个“高智商的API服务”或”超级大脑“来理解就足够了。
LLM的局限性
大模型幻觉
通俗来讲就是“大模型在一本正经的胡说八道”,它生成的回答看起来逻辑通顺、语气笃定,但内容却是完全虚构或者与事实不符;
大模型不擅长精确计算
在LLM眼中数字和符号只是文本片段(Token),而不是具有数学意义的数值变量,它并不是在调用CPU的算术逻辑单元进行计算,而是在做“文本接龙”。对于一些常见的数学表达式“1+1=2”模型可以给出正确的答案,但面对复杂、训练数据中不常见的计算表达式时,它只能根据概率学来预测这个结果,而不是真的执行了计算。
大模型的知识不具备实时性
大模型的知识完全来源于它的训练数据,训练数据都是来源于过去的知识。训练一个千亿级的参数模型需要耗费巨大的算力和数周的时间,一旦训练完成,它的参数就固定了,只是也就“冻结”了。比如某个模型的知识截止日期是2025年8月,那么在此之后的消息它就一无所知。
大模型的知识缺少局限性
大模型的知识来源于它的训练数据,所以它知道的东西取决于一个它的训练数据。因此不它仅有实时性的缺乏,还有训练样本的限制,它不可能知道所有的知识,例如公司内部规章制度、内部代码仓库等等信息都是开源大模型获取不到的知识。
提示词
在LLM的应用中,我们和模型对话的时候,给到模型的内容不叫question,也不叫request,而是叫prompt。
Prompt(提示词) 就是用户在输入给大语言模型的一段文本,用于引导模型生成期望的输出。它可以是一个问题、一段指令、一个上下文描述。它是我们与模型对话的“语言”,也是模型理解我们需求的钥匙。
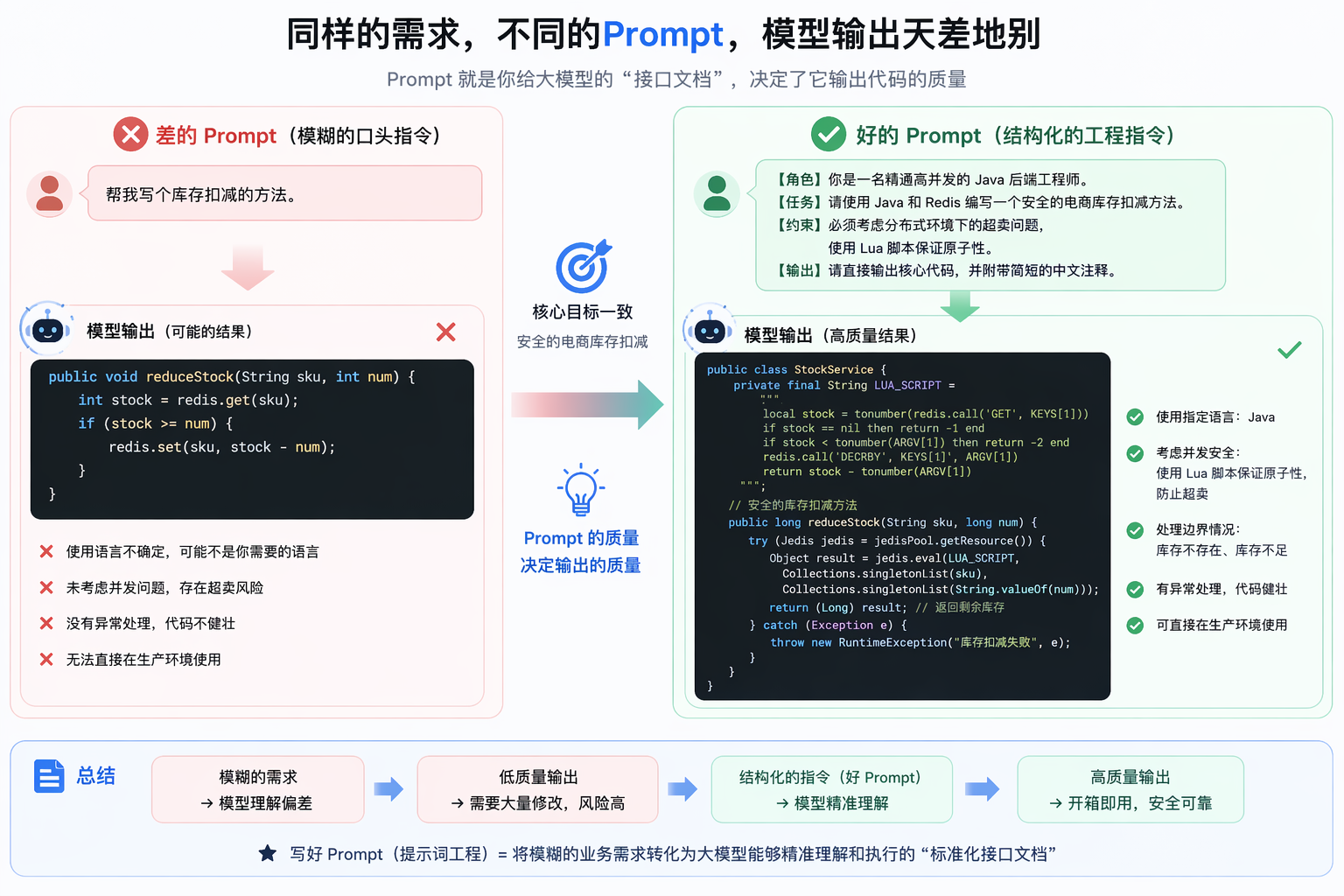
例如:我们让他写一个库存扣减的方法,不同的Prompt得到的结果是完全不同的,甚至有些结果根本就是不可用的:
Prompt的组成
一个好的Prompt(提示词)核心在于明确、具体、有约束,同时给模型留出发挥空间。常见的Prompt中包含以下几个方向:
- 角色(Role)
- 任务目标(Task/Goal)
- 背景/上下文(Context)
- 输出要求/格式(Format & Constraints)
- 输入数据(Input Data)
- 示例(Example/Few-Shot)
Prompt的标准化框架
Prompt的标准化框架,简单理解就是Prompt的一些标准化的模板,它由前人大量的实验数据归纳总结而来。
RTF(Role - Task - Fromat)框架
RTF是最基础的提示词模板,它主要强调三个核心要素:
- Role(角色):限定回复风格,专业度,口吻;
- Task(任务):明确要做什么、做到什么程度、有哪些边界;
- Format(输出格式):强制输出结构,便于后续自动解析;
例如,这是一个总结会议纪要的Prompt,它就是符合RTF模板的:
【Role】
你是一位拥有10年经验的董事会秘书,擅长将杂乱的信息快速整理成结构清晰、重点突出的专业会议纪要。
【Task】
请对下面提供的原始会议记录内容进行整理。你需要:
1. 提炼出会上达成的所有关键决定(Decisions)
2. 列出下一步要执行的具体行动项(Action Items),每个行动项需明确负责人
3. 删除所有无关的闲聊、重复或无结论的讨论内容
【Format】
请严格按照以下格式输出,不要添加任何额外解释:
=== 会议纪要 ===
**关键决定:**
- [决定1]
**行动项:**
| 任务内容 | 负责人 | 截止节点 |
|----------|--------|----------|
| xxx | xxx | xxx |
=== 原始会议记录 ===
(这里放置用户提供的原始文本)ICIO(Instruction - Context - Input - Output)框架
强调通过清晰分隔任务指令、背景信息、输入与输出要求,使模型在复杂场景中仍能搞笑执行。适合需要上下文理解或多阶段推理任务。
- Instruction(指令):你希望AI执行的具体任务
- Context(背景):提供上下文信息,帮助AI理解任务背景;
- Input Data(输入数据):告知AI需要处理的具体数据内容
- Output Indicator(输出指示):指定期望的输出类型或格式;
例如,下面是一段产品差评回复的Prompt提示词:
【Instruction 指令】
为下面这条用户差评,撰写一段客服回复文案。
【Context 背景】
你是一名电商平台的客服专员。该用户购买的是某款无线蓝牙耳机(售价199元)。差评内容主要反映“连接不稳定”和“充电口太紧”。公司政策:对连接问题,可引导用户重设或换货;对充电口问题,建议用户先尝试原装线缆。回复需要安抚用户情绪、表示歉意、提供可操作的解决方案,并邀请用户私信订单号以便进一步处理。语气温和专业。
【Input 输入数据】
用户差评原文:
“这耳机连手机老断,五分钟断两次,烦死了!充电口还特别紧,根本插不进去。再也不买了。”
【Output 输出指示】
回复文案控制在 120 字以内。开头先表达歉意与共情,中间给出两个问题的具体建议(重设配对 + 检查线缆/换货选项),最后引导私信。不要复制用户差评原文。CRISP(Capacity - Role - Insight - Statement - Personality - Experiment)
它通过对模型能力、角色、洞察、语气以及实验性的输出控制,使生成内容更具创造性和一致性,常用于学术、科研、内容创作等领域。
- Capacity:确定智能体的能力边界
- Role:明确身份定位
- Insight:提供必要的知识视角或洞察点,也就是上下文背景
- Statement:定义具体的任务目标,也就是Task
- Personality:设置个性化的语气与风格
- Experiment:指定探索性要求,如假设、生成多个答案等
# Capacity and Role(能力与角色)
你是一名资深市场策略分析师,擅长品牌定位与消费趋势洞察,熟悉零售行业的数据分析与竞争对比方法。
# Insight(洞察)
某科技品牌计划在明年推出一款主打AI功能的智能手表,目标群体为25-40岁的城市白领。
公司希望通过差异化策略抢占高端可穿戴设备市场。
# Statement(声明)
请撰写一份市场策略分析报告,包含以下内容:
1. 当前智能手表市场格局与主要竞争者分析
2. 目标用户画像与购买动机
3. 产品差异化与品牌定位建议
4. 三条可执行的市场推广策略
# Personality(个性)
请以专业咨询顾问的语气撰写,逻辑清晰、数据导向。
报告语言应简洁有力,避免空泛表达。
# Experiment(实验)
在报告结尾,请额外提供一个“创新性市场假设”,
例如:基于AI健康数据洞察的“主动健康推荐”功能,
并简要说明这一创新可能带来的商业价值与潜在风险。聊天记忆
在Agent(智能体)开发中,聊天记忆(Memory) 指的是Agent在多轮对话过程中保存、检索和利用历史信息的能力,使其能够保持上下文了连续性,而不是每次都像第一次见到用户一样回答。
Agent中记忆的分类
短期记忆(Short-Trem Memory)
短期记忆有时候也被叫做会话记忆(Conversation Memory)或者上下文记忆(Context Memory),它是指用户与模型的对话内容仅仅保持在当前会话中。
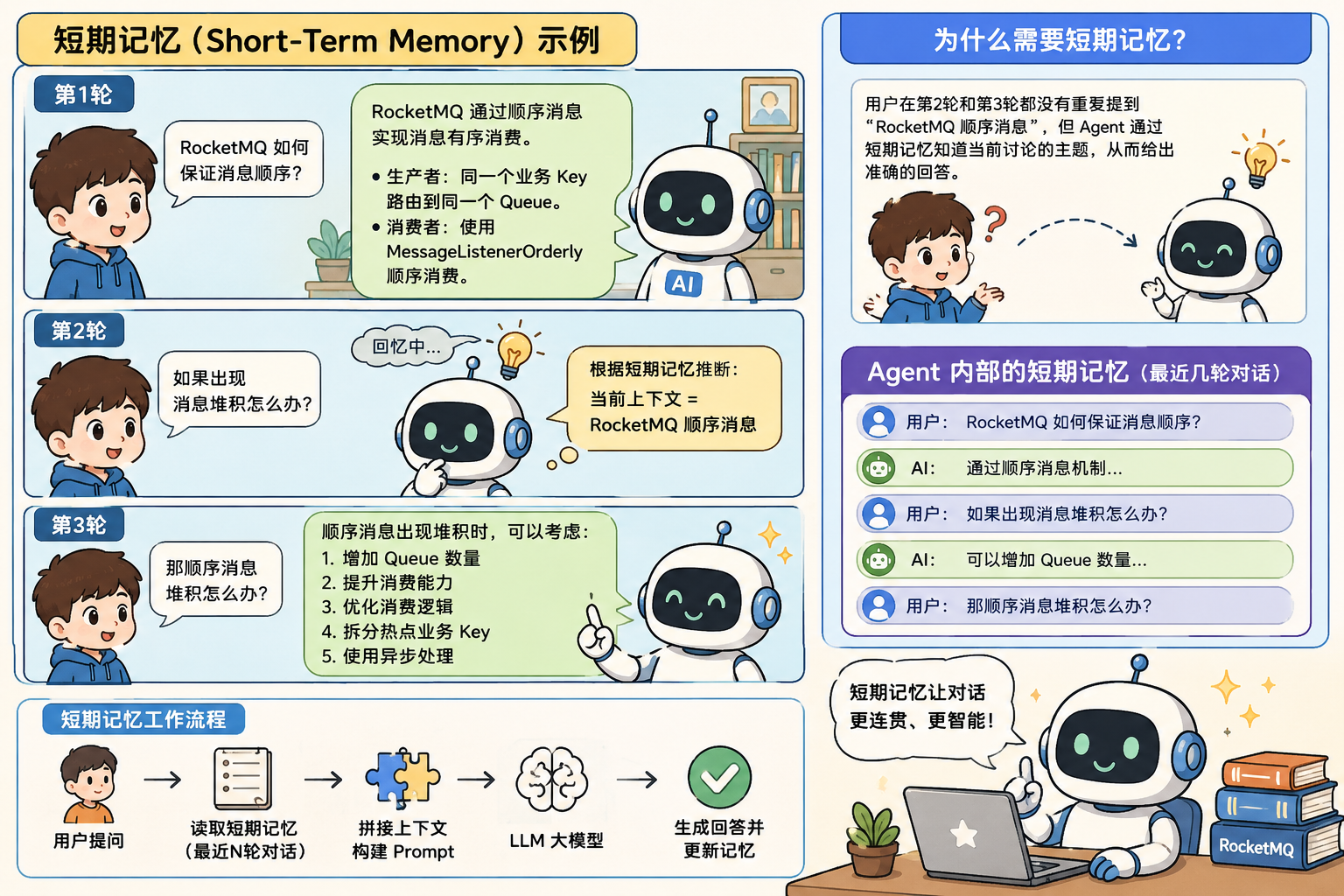
短期记忆的执行流程:
用户提问 --> 读取短期记忆 --> 拼接上下文 --> LLM大模型 --> 生成回答并且更新记忆整个短期记忆执行的过程中有几个比较关键的点:
- 短期记忆要怎么去存储?
- 选取哪些记忆的内容拼接到LLM大模型?
- 如何去模型的回答是否需要更新聊天记忆?
短期记忆实现的方式:
- 全量历史记录:保存当前会话的所有聊天记录;
- 滑动窗口:只保留最近N轮的聊天记录;
- Token窗口记忆:不按照固定的轮次,而是按照Token的数量来做滑动窗口;
- 摘要记忆:利用另外一个模型来总结历史会话记录生成摘要;
- 向量检索记忆:将记录存储到向量数据库中,后续的聊天会话从向量数据库中召回相关的聊天记录;
- 分层记忆:将记忆分为短期记忆、长期记忆和摘要记忆,三种记忆分别存储不同的内容的;
长期记忆(Long-Term Memory)
长期记忆就像是人类的知识库或者档案馆,它负责跨会话、跨时间地持久化存储信息。
长期记忆的核心作用:让Agent越用越聪明,它能记住用户的长期偏好、历史习惯、过往经验以及领域知识,实现个性化服务和持续成长。
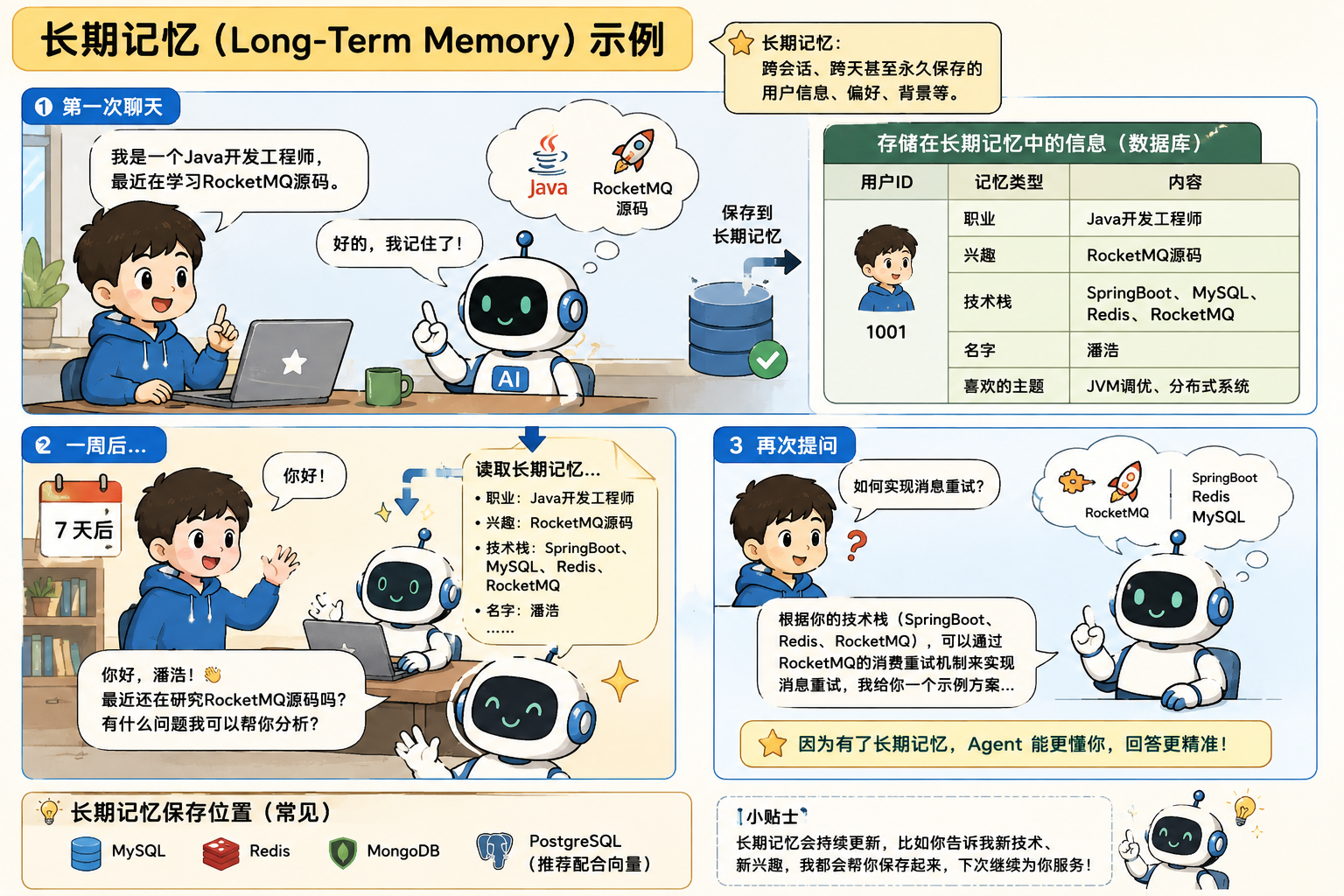
长期记忆的实现方式:
- 向量存储:目前最主流的方式,将聊天记忆存储在向量数据库中;
- 结构化存储:将用户画像、固定规则、偏好设置等存储到传统的关系型数据库中,保证高价值信息的绝对准确;
- 知识图谱:存储实体之间的复杂关系,帮助Agent进行逻辑推理
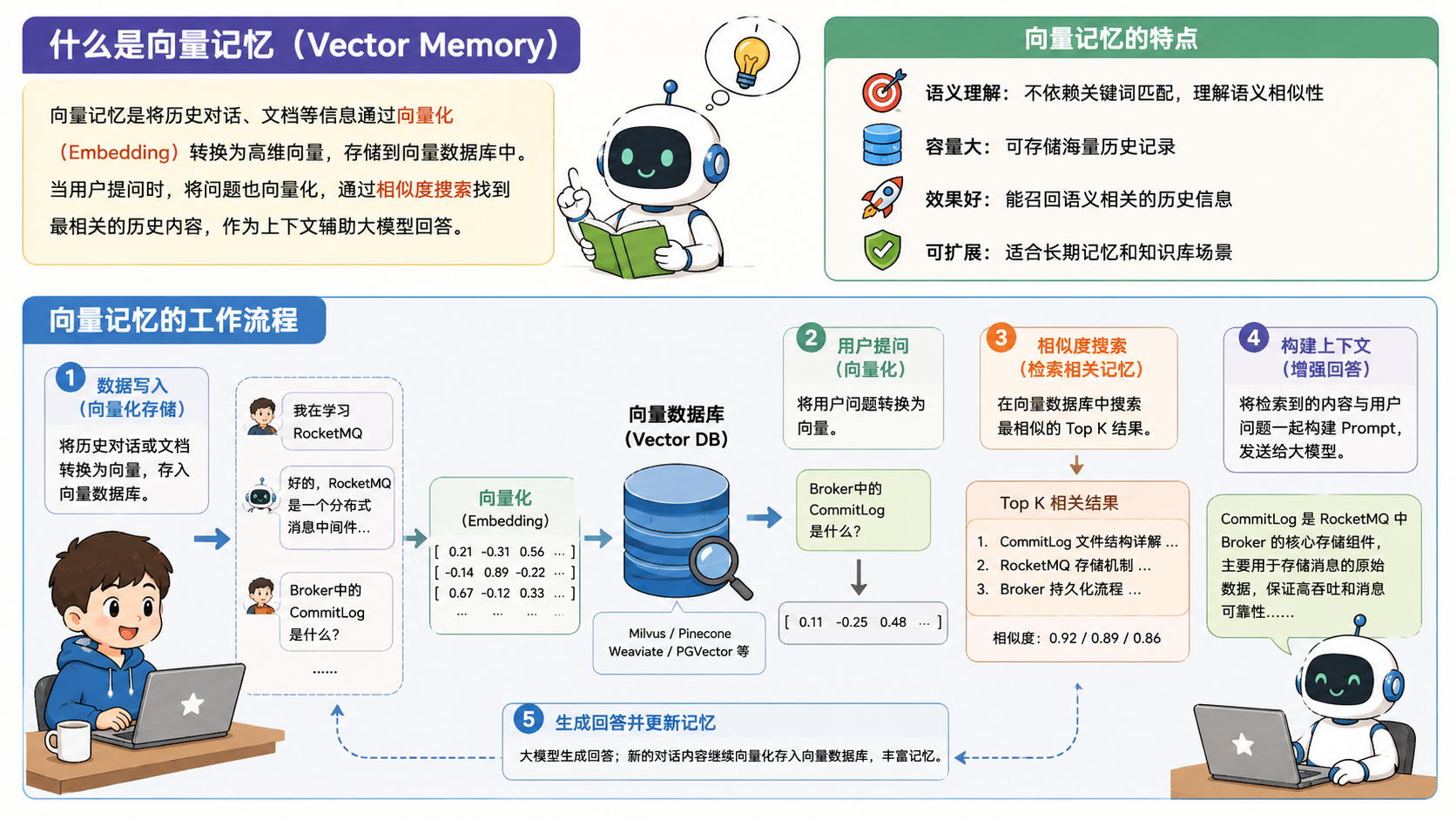
向量记忆(Vector Memory)
长期记忆和短期记忆主要是在记忆的内容和存储时长来区分的,但是向量记忆它是从存储介质的维度上来区分的。
向量记忆就将向量存储在向量数据库中的,每当接受到用户的请求的时候,根据用户请求的内容从向量数据库中召回相关的内容,然后拼装的到上下文中。
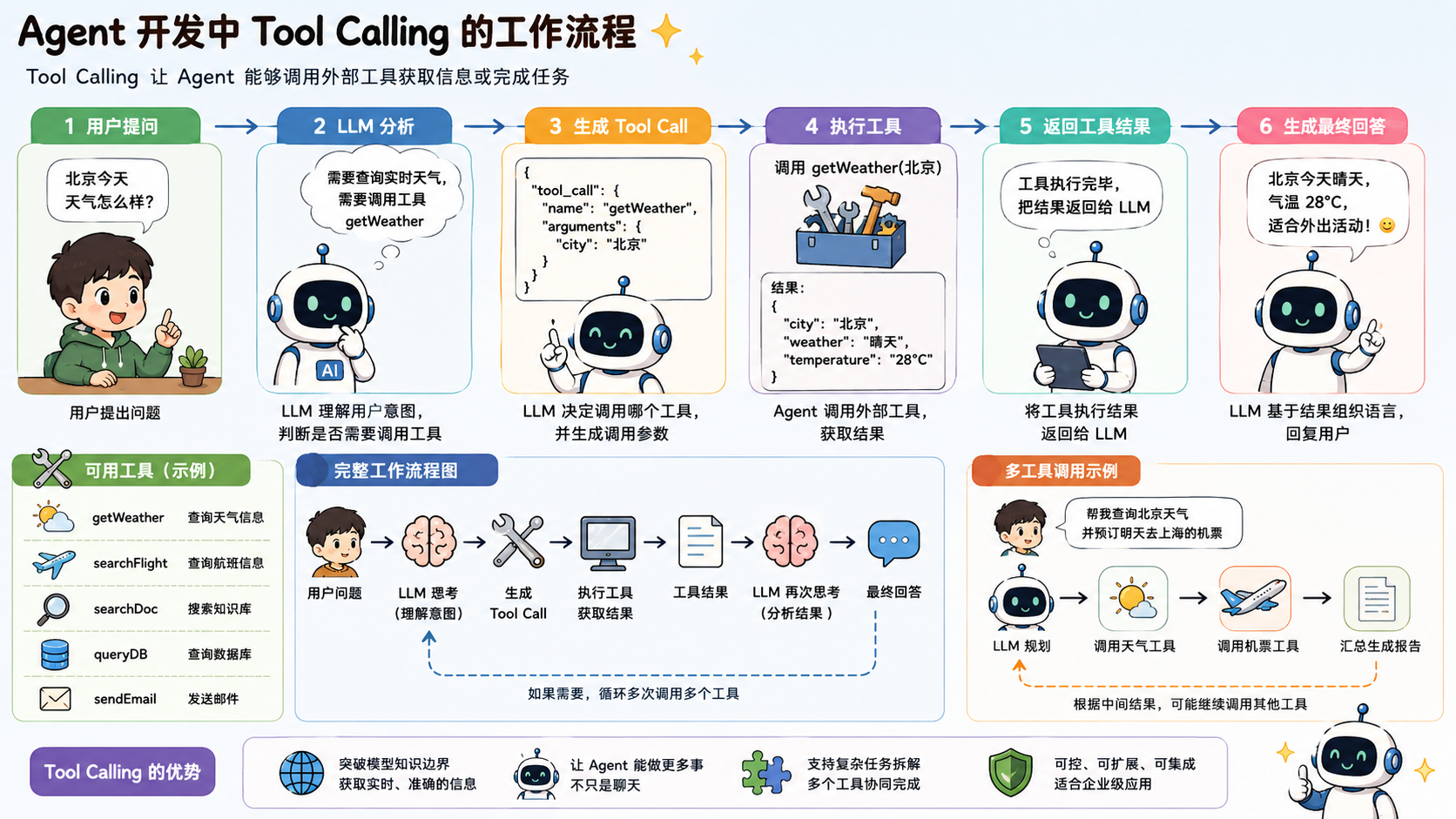
工具调用(Tool Calling)
Tool Calling也被称为Function Calling或者Function Call,这里称之为Tool Calling主要是因为在Spring AI的最新版本中,它已经将工具调用的能力封装成了Tool。
Tool本质上是将现实世界中的各种能力,封装成标准化的接口(如API、函数、脚本),让Agent能够调用并执行实际的操作。它可以概括为:
- 获取外部实时信息:让Agent能够突破自身训练数据的限制,去查询最新的天气、股票行情、新闻咨询或企业内部数据库;
- 执行实际操作:让Agent能够执行具体的指令,比如读取本地文件、发送电子邮件、调用业务系统API、操作CRM系统,甚至控制真实的物理设备;
- 扩展专业能力:封装一些LLM不擅长的复杂计算或专业逻辑,例如LLM直接做复杂数据计算容易出错,但调用一个计算器工具就能的得到绝对准确的结果。
Tool的执行步骤:
- 用户在提问的时候会告诉模型现在可用工具的列表;
- 模型根据用户的提问内容判断是否需要调用工具,如果是,则返回一个Tool Callback,其中包含工具的名称、参数信息等;
- Agent接受到模型返回的Tool Callback,就根据工具的名称和参数信息执行对应的工具(可能是一个本地方法,也可能是有一个RPC的调用);
- Agent将工具执行的结果再次返回给大模型;
- 大模型收工具执行的结果之后会,会利用“工具的结果 + 用户提问的内容”作为输入来回答用户的问题。